


Investing in Bitcoin: Is Now the Right Time to Enter the Market? Expert Insights & Analysis
Determining whether now is the right time to enter the Bitcoin market requires careful consideration of various factors, including market trends, price dynamics, fundamental analysis, and individual investment objectives. While…



































































































































Virtual Reality Therapy: Harnessing Immersive Technology to Address Mental Health Challenges, Psychological Disorders, and Pain Management in Healthcare Settings
Virtual Reality (VR) therapy harnesses immersive technology to address mental health challenges, psychological disorders, and pain management in healthcare settings. Here's how VR therapy works…

Digital Therapeutics: Harnessing Evidence-Based Interventions, Behavioral Modification Techniques, and Remote Monitoring for Chronic Disease Management
Digital therapeutics (DTx) harness evidence-based interventions, behavioral modification techniques, and remote monitoring technologies to manage…

Healthcare Chatbots: Improving Patient Engagement, Access to Information, and Administrative Efficiency through AI-Powered Conversational Interfaces
Healthcare chatbots are AI-powered conversational interfaces that play a crucial role in improving patient engagement,…
Augmented Reality in Medical Education: Transforming Learning Environments, Simulation Training, and Surgical Planning with Immersive Visualization Technologies
Augmented Reality (AR) is revolutionizing medical education by transforming learning environments, simulation training, and surgical…

Interoperability in Healthcare: Overcoming Technical, Organizational, and Regulatory Hurdles to Achieve Seamless Data Exchange, Care Coordination, and Patient-Centric Healthcare Delivery
Interoperability in healthcare is essential for achieving seamless data exchange, care coordination, and patient-centric healthcare…

Remote Surgery: Exploring Technological Advances, Ethical Considerations, and Clinical Outcomes in Teleoperated and Autonomous Surgical Procedures
Remote surgery, also known as telesurgery or teleoperated surgery, involves performing surgical procedures at a…

5G Connectivity in Healthcare: Accelerating Telemedicine Adoption, Remote Monitoring, and Point-of-Care Diagnostics with Ultra-Fast, Low-Latency Networks
5G connectivity in healthcare is poised to revolutionize telemedicine adoption, remote monitoring, and point-of-care diagnostics…

Healthcare Data Analytics: Leveraging Big Data, Machine Learning, and Predictive Analytics to Drive Insights, Improve Population Health, and Enhance Clinical Decision-Making
Healthcare data analytics harnesses big data, machine learning, and predictive analytics to drive insights, improve…

Securing Healthcare Data: Addressing Cybersecurity Threats, Compliance Requirements, and Data Protection Measures in an Era of Increasing Digitalization
Securing healthcare data is paramount in an era of increasing digitalization to protect patient privacy,…

Cybersecurity Challenges in Medical Devices: Ensuring Patient Safety, Regulatory Compliance, and Data Integrity in the Age of Connected Health Technologies
Cybersecurity challenges in medical devices pose significant risks to patient safety, regulatory compliance, and data…

Healthcare Robotics: Assisting Caregivers and Supporting Aging Populations
Healthcare robotics is rapidly advancing and playing a crucial role in assisting…

Population Health Management: Leveraging Big Data for Public Health Initiatives
Population health management involves using big data and analytics to understand and…

Internet of Medical Things (IoMT): Connected Devices and Healthcare Monitoring
The Internet of Medical Things (IoMT) refers to the network of interconnected…

Telemedicine and Remote Patient Monitoring: Enhancing Access and Outcomes
Telemedicine and remote patient monitoring (RPM) are innovative healthcare technologies that aim…

Data Analytics and Predictive Modeling in Healthcare: Improving Patient Outcomes
Data analytics and predictive modeling are playing a significant role in healthcare…
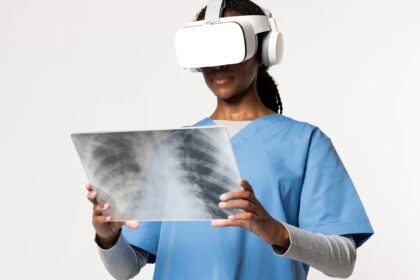
Virtual Reality in Healthcare: Therapy, Training, and Pain Management
Virtual reality (VR) technology is increasingly being used in healthcare to revolutionize…

Digital Health Apps and Wearables: Empowering Patients for Self-care
Digital health apps and wearables are empowering patients to take control of…

Harness The Power Of Technology In The Medical Sector For Senior Citizens
A common life needs medical assistance in many ways to lead a…

Cutting-Edge Technological Solutions Revolutionizing The Healthcare Sector
Healthcare sector is undergoing huge variations in recent days and the potential…

Healthcare Data Interoperability: Seamless Information Exchange for Better Care Coordination
Healthcare data interoperability refers to the ability of different healthcare systems, applications,…
Transformative Influence: Technology’s Dominance in Reshaping the Healthcare Landscape
A new era of telemedicine has been emerged with the advancements of…
Medical Tricorder: Pioneering a Paradigm Shift Towards Enhanced Healthcare Efficacy
If you take a survey then five out of every ten folk…

The Future of Healthcare Technology: Revolutionizing Patient Care
The future of healthcare technology holds tremendous potential for revolutionizing patient care.…
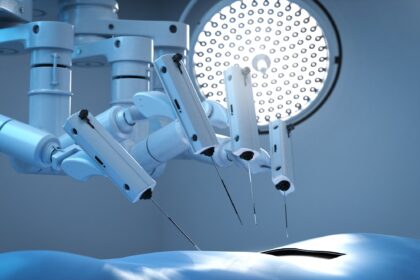
Enhancing Precision and Efficiency in Surgical Practices through Robotics in the Operating Room
Robotics in surgery has emerged as a transformative technology, offering enhanced precision,…
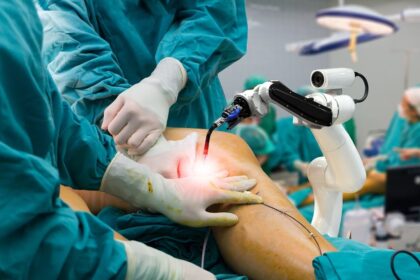
Enhancing Surgical Efficiency Through Robotics: The Role of Robots in Streamlining Procedures
Surgical robots are not a new name in the medical field. It…




















Elevating Efficiency: Exploring the Role of Robotic Process Automation (RPA) in Streamlining Insurance Operations and Claims Handling
Elevating Efficiency: Exploring the Role of Robotic Process Automation (RPA) in Streamlining Insurance Operations and Claims Handling" delves into how Robotic Process Automation (RPA) is…
Next-Generation Claims Management: The Convergence of Insurtech, Digital Transformation, and Customer-Centricity in Claims Services
Next-Generation Claims Management: The Convergence of Insurtech, Digital Transformation, and Customer-Centricity in Claims Services" explores how the integration of Insurtech, digital transformation, and customer-centric approaches is reshaping…

Quantum Leap: Peering into the Future of Insurance Technology with Quantum Computing and Predictive Analytics
Quantum Leap: Peering into the Future of Insurance Technology with Quantum Computing and Predictive Analytics" explores the potential of quantum computing and predictive analytics to revolutionize the…

Reimagining Property Protection: The Integration of IoT Devices and Smart Home Technology in Modern Insurance Solutions
Reimagining Property Protection: The Integration of IoT Devices and Smart Home Technology in Modern Insurance Solutions" explores how insurers are leveraging IoT devices and smart home technology…

Navigating the Regulatory Maze: A Roadmap for Insurance Insiders on Achieving Data Privacy Compliance and Regulatory Alignment
Navigating the Regulatory Maze: A Roadmap for Insurance Insiders on Achieving Data Privacy Compliance and Regulatory Alignment" provides guidance to insurance professionals on navigating the complex landscape…

AI-Powered Fraud Fighters: How Machine Learning Algorithms Are Reducing Insurance Fraud and Improving Claim Accuracy
AI-Powered Fraud Fighters: How Machine Learning Algorithms Are Reducing Insurance Fraud and Improving Claim Accuracy" explores the role of machine learning algorithms in detecting and preventing insurance…

Cybersecurity in the Spotlight: Decrypting the Complexities of Insuring Against Cyber Threats in the Digital Age
Cybersecurity in the Spotlight: Decrypting the Complexities of Insuring Against Cyber Threats in the Digital Age" focuses on the evolving landscape of cyber threats and the challenges…

Beyond the Buzzwords: Unraveling the Practical Applications of Insurtech Partnerships and Collaborations for Industry Innovation
Beyond the Buzzwords: Unraveling the Practical Applications of Insurtech Partnerships and Collaborations for Industry Innovation" delves into the tangible applications and real-world impact of insurtech partnerships and…

Personalized Protection: Customizing Insurance Products to Address Unique Consumer Needs and Lifestyle Preferences
Personalized Protection: Customizing Insurance Products to Address Unique Consumer Needs and Lifestyle Preferences" explores how insurers are tailoring insurance products to meet the diverse needs and preferences…

Weathering the Storm: Building Climate Resilience Through Advanced Climate Risk Modeling and Insurance Solutions
Weathering the Storm: Building Climate Resilience Through Advanced Climate Risk Modeling and Insurance Solutions" examines the importance of climate resilience and the role of advanced climate risk…
Insurtech Startups: Driving Innovation and Disruption in the Insurance Market
Insurtech startups are playing a pivotal role in driving innovation and disruption in…

Phases You Must Know About Insurance Technology Solutions
Integrity, excellence and reliability are the major aspects which a business seeks for…

Microinsurance and Insurtech: Extending Insurance Coverage to the Underinsured
Microinsurance, coupled with insurtech, has the potential to extend insurance coverage to the…

Blockchain Technology in Insurtech: Enhancing Security and Trust in Insurance
Blockchain technology is revolutionizing the insurtech industry by enhancing security, transparency, and trust…

Insurtech Partnerships: Collaboration between Traditional Insurers and Tech Startups
Insurtech partnerships between traditional insurers and tech startups are becoming increasingly common and…

The Future of Insurtech Regulation: Balancing Innovation and Consumer Protection
The future of insurtech regulation will revolve around finding the right balance between…

Technology Transformation: Disrupting and Innovating the Insurance Sector
Insurtech is a proper blend of innovation and insurance sector. Technologies have a…
Technological Innovations Revolutionizing the Insurance Industry Landscape
Present era is completely digitized where consumers demand a fast pace solution for…

Cyber Insurance: Addressing the Growing Threat of Cyber Risks
Cyber insurance is a type of insurance coverage that helps businesses and individuals…

Digital Distribution Channels in Insurtech: Reimagining Customer Engagement
Digital distribution channels in insurtech are revolutionizing the way insurance products are marketed,…

Climate Change and Insurtech: Adapting Insurance Solutions to Environmental Risks
Climate change has a profound impact on the insurance industry, and insurtech plays…

On-Demand Insurance: Flexible Coverage for the Digital Age
On-demand insurance is a modern insurance model that offers flexible and temporary coverage…

Future Forward: Trends in Insurance Technology Shaping Tomorrow’s Landscape
Insurance was one of the technologies which were totally manual based which was…

Emerging Trends and Innovations Shaping the Insurance Sector Landscape
Insurance sector was one of those sectors which were untouched from the advancements…











Enhancing Online Shopping Experiences: Leveraging Augmented Reality for Immersive Product Visualization in the CPG Space
Leveraging augmented reality (AR) for immersive product visualization in the consumer packaged goods (CPG) space can significantly enhance the online shopping experience, allowing consumers to…
Navigating the Digital Revolution: Key Considerations and Best Practices for Retailers Embarking on Transformational Journeys
The digital revolution has fundamentally transformed the retail landscape, reshaping consumer behavior, expectations, and preferences. To thrive in this rapidly evolving environment, retailers must embark on…
Blurring the Lines Between Online and Offline: Strategies for Retailers to Embrace Digital Transformation and Stay Competitive
The retail landscape is undergoing a significant transformation as digital technologies continue to reshape consumer behavior and expectations. To stay competitive in this evolving environment, retailers…

Digitizing the Supply Chain: Leveraging Technology to Improve Visibility, Efficiency, and Resilience for Retail Operations
The modern retail landscape is characterized by complexity, with supply chains spanning multiple geographies and involving numerous stakeholders. To navigate this complexity and stay competitive, retailers…

Streamlining E-commerce Operations: The Role of Automation in Fulfillment Processes for Retailers
In the dynamic world of e-commerce, efficiency in fulfillment processes is paramount for retailers to meet customer expectations and stay competitive. Automation plays a pivotal role…

Predictive Insights: How Machine Learning Algorithms Are Revolutionizing Demand Forecasting for CPG Companies
In the fast-paced world of Consumer Packaged Goods (CPG), accurate demand forecasting is critical for optimizing inventory levels, minimizing stockouts, and meeting customer expectations. Traditional forecasting…

Personalized Marketing in the Digital Age: Leveraging Data-Driven Strategies to Engage and Retain Customers in Retail
In today's digital age, consumers expect personalized experiences from the brands they interact with. Personalized marketing, powered by data-driven strategies, has become a cornerstone of successful…

Optimizing Manufacturing Processes: The Integration of Robotic Automation for Efficiency and Quality Assurance in CPG
In the dynamic landscape of Consumer Packaged Goods (CPG) manufacturing, optimizing processes is crucial for maintaining competitiveness and meeting evolving consumer demands. The integration of robotic…

The Social Commerce Phenomenon: Understanding its Impact and Strategies for Retailers and CPG Brands to Capitalize
The emergence of social commerce, the integration of social media and e-commerce, has significantly transformed the retail landscape. Understanding its impact and devising strategies to capitalize…

Immersive Retail: Exploring the Role of Augmented Reality Technology in Redefining the In-Store Shopping Experience
In today's digital age, retailers are leveraging augmented reality (AR) technology to transform the in-store shopping experience into an immersive and interactive journey. By blending digital…

Enhancing Online Shopping Experiences: Leveraging Augmented Reality for Immersive Product Visualization in the CPG Space
Leveraging augmented reality (AR) for immersive product visualization in the consumer packaged goods (CPG) space can significantly enhance the online shopping experience, allowing consumers to interact…

Internet of Things (IoT) in Retail: Connected Stores and Smart Shelf Management
The Internet of Things (IoT) is revolutionizing the retail industry by enabling connected stores and smart shelf management.…

Data Analytics and Predictive Modeling in Retail: Understanding Consumer Behavior
Data analytics and predictive modeling are powerful tools in the retail industry that help businesses understand and predict…

Do consumer interaction ways are changing for the retailer, if yes then how?
Since the pandemic hit the world, almost all business sectors have gone through a noticeable change and the…

Social Commerce: Influencer Marketing and Shoppable Social Media
Social commerce refers to the merging of social media and e-commerce, where social media platforms are used as…

The Retail Revolution Unfolds: A Comprehensive Exploration of the Profound Evolution Reshaping Consumer Markets
Retail is constantly transforming its face and now with latest four revolutions a great enhancement has been noticed…

Omni-channel Retailing: Seamless Integration of Online and Offline Shopping
Omni-channel retailing refers to the seamless integration of online and offline shopping channels to provide customers with a…

Massive $150 Million Series E Investment Fuels Locus Robotics’ Growth Trajectory
The E-commerce sector is growing at a fast pace and the workforce working every moment for this success…

Personalization and Customer Loyalty Programs in the Digital Age
Personalization and customer loyalty programs have become essential strategies for businesses in the digital age. Here's how these…

Inventory Management and Demand Forecasting with Big Data
Inventory management and demand forecasting are critical aspects of supply chain management, and big data analytics has revolutionized…

Embracing Change: The Imminent Revolution Set to Transform the Retail Landscape
In the present era of technological advancements each sector is growing at a fast pace. Retail is one…
Blockchain in Retail: Ensuring Transparency in Supply Chain and Product Authentication
Blockchain technology is transforming the retail industry by ensuring transparency in the supply chain and enhancing product authentication.…

Voice Commerce: The Rise of Virtual Assistants and Voice-Activated Shopping
Voice commerce, driven by virtual assistants and voice-activated shopping, is gaining prominence as a convenient and intuitive way…

How Retail Sector Can Hold Their Customers For The Long Term & Reduce Their Expenses?
Since 2020, the world has undergone a lot of changes and a leap in the e-commerce sector. Where…
The Future of Retail Technology: Transforming the Shopping Experience
The future of retail technology is poised to revolutionize the shopping experience for both online and brick-and-mortar retailers.…



































Revolutionizing Customer Service in Banking: The Emergence and Advantages of AI-Powered Chatbots
In recent years, the banking sector has witnessed a paradigm shift in customer service with the emergence of AI-powered chatbots. These intelligent virtual assistants are…

Unlocking Innovation with Open Banking APIs: Fostering Collaboration and Accelerating Development in the BFSI Sector
Open Banking APIs have emerged as powerful tools for fostering collaboration, driving innovation, and accelerating development in the Banking, Financial Services, and Insurance (BFSI) sector.…

AI-Powered Wealth Management Solutions: Empowering Financial Advisors with Intelligent Insights and Recommendations
Artificial Intelligence (AI) is revolutionizing the wealth management industry by empowering financial advisors with intelligent insights and personalized recommendations. These AI-powered solutions leverage advanced algorithms,…

The Future of Mobile Payments: Trends, Technologies, and their Implications for the BFSI Sector
Mobile payments have emerged as a transformative force in the financial services landscape, offering convenience, speed, and accessibility to consumers worldwide. As technology continues to…
Insurtech Innovations: How Technology is Transforming the Insurance Landscape
The insurance industry is undergoing a significant transformation driven by technological advancements and innovation. Insurtech, a term used to describe technology-enabled innovations in insurance, is…

Enhancing Security in Financial Services: Leveraging Artificial Intelligence for Fraud Detection and Prevention
In an increasingly digital world, financial services are faced with escalating cybersecurity threats, particularly in the realm of fraud. As traditional methods of fraud detection…

Personalized Financial Services Apps: Enhancing Customer Experience through Data-Driven Insights
In today's digital age, financial services apps are at the forefront of delivering personalized experiences to customers. By harnessing the power of data-driven insights, these…
Robo-Advisors: Transforming Wealth Management Practices through Automated and Data-Driven Solutions
Robo-advisors have emerged as disruptive forces in the wealth management industry, revolutionizing traditional practices through automation and data-driven solutions. These digital platforms utilize algorithms and…

Quantum Computing: Exploring its Potential Applications in Financial Modeling and Analysis for the BFSI Sector
Quantum computing has emerged as a disruptive technology with the potential to revolutionize various industries, including the Banking, Financial Services, and Insurance (BFSI) sector. Its…
Real-Time Payments: Accelerating Transactions and Driving Financial Inclusion in the Digital Economy
Real-time payments have emerged as a transformative force in the digital economy, offering instant, seamless, and secure transactions that enable individuals and businesses to exchange…

Navigating Regulatory Challenges: Safeguarding Data Privacy in the BFSI Sector
The Banking, Financial Services, and Insurance (BFSI) sector handle vast amounts of sensitive financial and personal data, making data privacy a paramount concern. Regulatory frameworks…

Big Data Analytics in Fintech: Leveraging Data for Personalized Financial Services
Big data analytics has revolutionized the fintech industry by enabling financial institutions to leverage vast amounts of data to provide personalized financial services. Here's…

Cybersecurity in an Evolving Landscape: Strategies for CIOs in BFSI
"Cybersecurity in an Evolving Landscape: Strategies for CIOs in BFSI" is a hypothetical guidebook that could provide Chief Information Officers (CIOs) within the Banking,…

Cybersecurity in Fintech: Addressing Risks and Protecting Financial Data
Cybersecurity is a critical aspect of fintech, as the industry deals with sensitive financial data and operates in a digital ecosystem. Fintech companies must…

Cryptocurrencies and the Future of Money: Exploring the Potential of Digital Currencies
Cryptocurrencies have gained significant attention and are shaping the future of money and financial systems. Here's an exploration of the potential of digital currencies:…

Robo-Advisors and Automated Investing: Shaping the Future of Wealth Management
Robo-advisors and automated investing are indeed shaping the future of wealth management. These technologies leverage artificial intelligence, machine learning, and data analysis to provide…

Biometric Authentication in FinTech: Enhancing Security & User Experience
Biometric authentication has become increasingly prevalent in fintech, offering enhanced security and improved user experience. By leveraging unique biological or behavioral characteristics, biometrics provide…

Regulatory Sandboxes: Fostering Innovation in Fintech and Financial Services
Regulatory sandboxes are initiatives established by regulatory authorities to foster innovation in the fintech and financial services industry. They provide a controlled environment where…

Robo-Advisor and its key benefits in Financial Technology
Financial planning is the backbone for every type of business to operate efficiently to achieve the targeted objective. A single mistake in the financial…
Contactless Payments and NFC Technology: The Future of Retail Transactions
Contactless payments and Near Field Communication (NFC) technology are reshaping the future of retail transactions. Here's how they are transforming the way we pay:…

The Rise of Decentralized Finance (DeFi): Disrupting Traditional Financial Systems
Decentralized Finance, commonly known as DeFi, refers to the use of blockchain technology and cryptocurrencies to recreate traditional financial systems in a decentralized manner.…

Neobanks: Redefining Banking for the Digital Age
Neobanks, also known as digital banks or challenger banks, are innovative financial institutions that operate exclusively online without any physical branch network. These digital-first…

Artificial Intelligence (AI) in Fintech: Revolutionizing Financial Services
Artificial Intelligence (AI) has indeed revolutionized the financial services industry, including the field of fintech (financial technology). AI technologies have brought about significant advancements…





















Beyond Bitcoin: Exploring the Potential of Blockchain Technology in Real-World Applications
Beyond Bitcoin: Exploring the Potential of Blockchain Technology in Real-World Applications" delves into the various practical applications of blockchain technology beyond cryptocurrencies like Bitcoin. Here's…
Cross-Chain Communication: Enabling Seamless Asset Transfers Across Different Blockchains
Cross-Chain Communication: Enabling Seamless Asset Transfers Across Different Blockchains" explores the technology and protocols facilitating interoperability between distinct blockchain networks, allowing for the frictionless transfer of assets…

Tokenomics 101: Demystifying Token Economics and Value Creation in Blockchain Projects
Tokenomics 101: Demystifying Token Economics and Value Creation in Blockchain Projects" provides an introductory overview of token economics, exploring the principles, mechanisms, and factors that contribute to…

The Role of Oracles in Smart Contracts: Ensuring Trustworthy Data Feeds for Decentralized Applications
The Role of Oracles in Smart Contracts: Ensuring Trustworthy Data Feeds for Decentralized Applications" explores the significance of oracles in smart contract ecosystems, focusing on their role…

Carbon Neutral Cryptocurrency: Addressing Environmental Concerns in Blockchain Mining
Carbon Neutral Cryptocurrency: Addressing Environmental Concerns in Blockchain Mining" explores the initiatives and technologies aimed at mitigating the environmental impact of blockchain mining activities, particularly in terms…
Privacy Coins: Balancing Privacy and Regulatory Compliance in Cryptocurrency Transactions
Privacy Coins: Balancing Privacy and Regulatory Compliance in Cryptocurrency Transactions" explores the unique challenges and considerations associated with privacy-focused cryptocurrencies, commonly known as privacy coins. Here's an…

Investing in Bitcoin: Is Now the Right Time to Enter the Market? Expert Insights & Analysis
Determining whether now is the right time to enter the Bitcoin market requires careful consideration of various factors, including market trends, price dynamics, fundamental analysis, and individual…

Navigating the Cryptocurrency Market: Strategies for Successful Long-Term Investment
Navigating the Cryptocurrency Market: Strategies for Successful Long-Term Investment" explores various approaches and best practices for investors looking to build a successful long-term investment strategy in the…

The Emergence of Central Bank Digital Currencies (CBDCs): Implications for the Future of Money
The Emergence of Central Bank Digital Currencies (CBDCs): Implications for the Future of Money" explores the rise of CBDCs and their potential impact on the global financial…

Top 5 Altcoins to Watch in 2024: Potential Gems for Your Investment Portfolio
Chainlink (LINK): Chainlink is a decentralized oracle network that aims to connect smart contracts with real-world data. It enables blockchain platforms to securely interact with external data…

Blockchain Gaming: The Convergence of Gaming and Cryptocurrency in Virtual Economies
Blockchain Gaming: The Convergence of Gaming and Cryptocurrency in Virtual Economies" explores the intersection of blockchain technology and gaming, highlighting the emergence of virtual economies and decentralized…

Web3.0: The Decentralized Web and Its Potential to Reshape the Internet Landscape
Web3.0: The Decentralized Web and Its Potential to Reshape the Internet Landscape" explores the emerging paradigm of Web3.0, characterized by decentralized architectures, blockchain technology, and user-centric principles.…

Risk Management in Cryptocurrency Investment: Mitigating Volatility and Maximizing Returns
Risk management is essential in cryptocurrency investment due to the high volatility and inherent uncertainties associated with digital assets. Here's a guide on mitigating volatility and maximizing…

Governance in Blockchain Networks: Ensuring Consensus and Decision-Making
Governance in blockchain networks refers to the processes and mechanisms through which decisions are made, rules are established, and consensus is reached among network participants. Effective governance is crucial for maintaining the…

Blockchain Intermediaries: Reshaping Traditional Business Models
Blockchain intermediaries are entities that use blockchain technology to facilitate transactions between parties without the need for a central authority or traditional intermediary. They are reshaping traditional business models by providing new…

Blockchain Security: Addressing Vulnerabilities and Threats
Blockchain technology provides a secure and transparent way to store and transfer data. However, it is not immune to security vulnerabilities and threats. Here are some of the most common security vulnerabilities…

Blockchain and Data Management: Ensuring Integrity and Consistency
Blockchain technology can be used for data management to ensure the integrity and consistency of data. By leveraging blockchain's decentralized and immutable ledger, data can be securely stored, verified, and shared across…

Blockchain and Intellectual Property: Addressing Copyright and Ownership Challenges
Blockchain technology has the potential to revolutionize the management of intellectual property (IP) rights, particularly in the areas of copyright and ownership. However, it also presents certain challenges that need to be…

Navigating the Blockchain Landscape: Addressing Challenges and Overcoming Hurdles
Blockchain is one of the latest technologies emerging out as a boon for various trading and finance companies. This technology is summarized as a digital ledger of online transactions decentralized to open…
Blockchain in Supply Chain: Challenges and Solutions for Traceability and Transparency
Blockchain technology has the potential to revolutionize supply chain management by providing enhanced traceability and transparency. However, there are several challenges that need to be addressed to effectively implement blockchain in supply…

Interoperability in Blockchain: Bridging the Gap Between Different Networks
Interoperability in blockchain refers to the ability of different blockchain networks to communicate, share data, and interact with each other seamlessly. Achieving interoperability is crucial for the widespread adoption of blockchain technology…

Essential Insights: Preparing for Blockchain Onboarding with Key Considerations
Blockchain is one of the recently emerging technologies opted by a number of folks. But the reach of blockchain connection is still limited due to lack of knowledge about the technology, it…

Topic of interest in blockchain technology
Bockchain technology is gaining popularity in recent years and is able to attain attention of techies. It can be defined as a digital ledger having details of every single transaction. This digital…

Energy Efficiency in Blockchain: Overcoming Environmental Concerns
Energy efficiency is a significant concern in blockchain technology due to the computational power required for consensus mechanisms and the energy consumption of mining activities, particularly in proof-of-work (PoW) based blockchains. Here…

Scalability in Blockchain: Overcoming Challenges for Mass Adoption
Scalability is one of the most significant challenges facing blockchain technology and its mass adoption. Here are some challenges associated with scalability in blockchain technology and potential solutions to overcome them: Slow…
Everything you need to know about blockchain
Image by rawpixel.com If you are closely related to banking and finance, then you might have come across a word blockchain in the recent decade. Most of the folks get confused with its…




















Artificial Creativity Unleashed: Exploring AI’s Role in Transforming the Creative Industries, From Music Composition to Visual Arts
Artificial Creativity Unleashed: Exploring AI's Role in Transforming the Creative Industries, From Music Composition to Visual Arts" delves into the burgeoning intersection of artificial intelligence…

Addressing Bias in Artificial Intelligence : CIOs’ Efforts in Mitigating Algorithmic Discrimination
Addressing bias in AI is critical for ensuring that these systems are accurate, effective, and ethical. CIOs (Chief Information Officers) play a crucial role in mitigating algorithmic discrimination by ensuring…
Artificial Intelligence in Smart Cities: Transforming Urban Living with Intelligent Technologies
Artificial Intelligence (AI) has the potential to transform urban living through the development of smart cities. Here are some ways AI is being used to create intelligent cities: Traffic Management:…

Regulatory Compliance in the Era of AI: CIOs’ Guide to Navigating Legal and Privacy Requirements
As the use of artificial intelligence (AI) becomes more widespread, regulatory compliance is becoming increasingly important. CIOs (Chief Information Officers) play a critical role in ensuring that AI systems are…

Navigating the Ethical Challenges of AI: CIOs’ Role in Ensuring Responsible AI Adoption
As artificial intelligence (AI) continues to transform industries and society, there are growing concerns about the ethical implications of its use. Chief Information Officers (CIOs) have an essential role in…
Transformative Education: Harnessing the Full Potential of AI for Personalized Learning, Adaptive Teaching, and Lifelong Skill Development
Transformative Education: Harnessing the Full Potential of AI for Personalized Learning, Adaptive Teaching, and Lifelong Skill Development" explores the intersection of artificial intelligence (AI) and education, highlighting how AI technologies…

AI Adoption: From Hype to Practical Application, Examining the Latest Trends, Challenges, and Opportunities Across Industries
AI Adoption: From Hype to Practical Application, Examining the Latest Trends, Challenges, and Opportunities Across Industries" explores the journey of artificial intelligence (AI) from its initial hype to its practical…

The Future of AI in Legal Practice: Ethical and Legal Challenges to Consider
AI is already making an impact on the legal profession, with applications ranging from document analysis and e-discovery to contract management and legal research. However, the use of AI in…

Artificial Intelligence & Creativity: Advancements, Copyright, & Intellectual Property
AI has shown promise in augmenting human creativity in various fields, including art, music, literature, and design. AI-generated content can also raise important questions around copyright and intellectual property. Here…

Artificial Intelligence & Emotional Intelligence: Exploring the Intersection of Technology & Human
Artificial Intelligence (AI) is often thought of as a purely technical and analytical field, but there is increasing interest in exploring the intersection of technology and human emotions, often referred…

The Role of CIOs in AI Governance: Strategies for Establishing Ethical AI Practices
As AI becomes increasingly pervasive in organizations, it is important to establish ethical AI practices to ensure that AI systems are developed and used in a responsible and ethical manner.…

Quantum AI: Unlocking the Power of Quantum Computing for AI Applications
Quantum AI is an emerging field that combines the power of quantum computing with artificial intelligence. Quantum computing, which uses quantum bits (qubits) to perform complex calculations, has the potential…

Managing Data Quality for Artificial Intelligence Success: Challenges and Best Practices for CIOs
As the use of artificial intelligence (AI) becomes more widespread, managing data quality is becoming increasingly important. Data quality is essential for the success of AI models, as the accuracy…

Climate Intelligence: Leveraging AI to Tackle Climate Change Challenges and Foster Sustainability
Climate Intelligence: Leveraging AI to Tackle Climate Change Challenges and Foster Sustainability" explores the intersection of artificial intelligence (AI) and climate change mitigation, highlighting how AI technologies can be utilized…

AI Governance in the Digital Era: Crafting Policies and Regulations to Ensure Responsible Development and Deployment of AI Technologies
AI Governance in the Digital Era: Crafting Policies and Regulations to Ensure Responsible Development and Deployment of…

Smart Cities Redefined: AI-Driven Urban Planning, Infrastructure Optimization, and Citizen Services in the Smart Cities
Smart Cities Redefined: AI-Driven Urban Planning, Infrastructure Optimization, and Citizen Services" explores the transformative role of artificial…

Sports Analytics 2.0: The Role of AI in Enhancing Performance Analysis, Talent Identification, and Fan Engagement
Sports Analytics 2.0: The Role of AI in Enhancing Performance Analysis, Talent Identification, and Fan Engagement" delves…

Cyber AI: Fortifying Digital Defenses Against Sophisticated Cyber Threats with AI-Powered Security Solutions
Cyber AI: Fortifying Digital Defenses Against Sophisticated Cyber Threats with AI-Powered Security Solutions" explores the critical role…

AI-Powered Policing: Striking the Balance Between Public Safety and Civil Liberties with Predictive Policing Technologies
AI-Powered Policing: Striking the Balance Between Public Safety and Civil Liberties with Predictive Policing Technologies" delves into…

Symbolic AI Resurgence: Bridging the Gap Between Deep Learning and Symbolic Reasoning for Advanced AI Capabilities
Symbolic AI Resurgence: Bridging the Gap Between Deep Learning and Symbolic Reasoning for Advanced AI Capabilities" explores…

Space Intelligence: How AI is Revolutionizing Space Exploration, Satellite Communications, and Astronaut Assistance
Space Intelligence: How AI is Revolutionizing Space Exploration, Satellite Communications, and Astronaut Assistance" explores the innovative ways…

The Evolution of AI Oversight: From Ethics Boards to Regulatory Frameworks, Addressing the Challenges of AI Governance
The Evolution of AI Oversight: From Ethics Boards to Regulatory Frameworks, Addressing the Challenges of AI Governance"…
Mindful Machines: How AI is Transforming Mental Health Diagnosis, Therapy, and Support Systems
Mindful Machines: How AI is Transforming Mental Health Diagnosis, Therapy, and Support Systems" explores the intersection of…

Inclusive Technology: Empowering Persons with Disabilities Through AI-Driven Assistive Technologies and Accessibility Solutions
Inclusive Technology: Empowering Persons with Disabilities Through AI-Driven Assistive Technologies and Accessibility Solutions" explores the transformative role…

Agriculture 4.0: AI-Driven Precision Farming, Crop Monitoring, and Sustainable Agriculture Practices Redefining the Agri-Tech Landscape
Agriculture 4.0: AI-Driven Precision Farming, Crop Monitoring, and Sustainable Agriculture Practices Redefining the Agri-Tech Landscape" explores the…

Quantum AI: Charting the Future of Artificial Intelligence with Quantum Computing Advancements and Breakthroughs
Quantum AI: Charting the Future of Artificial Intelligence with Quantum Computing Advancements and Breakthroughs" explores the intersection…

AI-Generated Narratives: Exploring the Impact of AI-Authored Content on Journalism, Storytelling, and Media Production
AI-Generated Narratives: Exploring the Impact of AI-Authored Content on Journalism, Storytelling, and Media Production" delves into the…









Proactive Customer Service: Anticipating Needs and Resolving Issues Before They Arise
Proactive customer service involves anticipating customer needs and resolving issues before they arise, enhancing satisfaction and loyalty. Here's how businesses can implement proactive customer service…

CEM 2.0: Redefining Customer Experience Strategies for the Digital Age
Customer Experience Management (CEM) 2.0 represents a paradigm shift in how businesses approach customer experience strategies, leveraging digital technologies and data-driven insights to create personalized, seamless, and engaging customer…

Personalized Recommendations and Customer Experience: Harnessing the Power of AI and Algorithms
Personalized recommendations powered by AI and algorithms have become integral to enhancing the customer experience. By analyzing vast amounts of data, AI algorithms can identify patterns, preferences, and behavior…

Internet of Things (IoT) and Customer Experience: Creating Connected Experiences
The Internet of Things (IoT) has the potential to transform customer experiences by creating connected experiences. By integrating IoT devices and data, companies can collect real-time information about their…

Gaming and Gamification in Customer Experience: Driving Engagement and Loyalty
Gaming and gamification are increasingly being used by businesses to enhance the customer experience and drive engagement and loyalty. Gamification is the use of game mechanics and design in…

The Future of Customer Feedback: Innovations in Surveys, Sentiment Analysis, and Voice of the Customer
The future of customer feedback is being shaped by new technologies and innovative approaches to gathering and analyzing customer feedback. Here are some of the trends and innovations that…

The Rise of Voice Commerce: Enhancing Customer Engagement and Convenience
The rise of voice commerce, facilitated by virtual assistants and smart speakers, is transforming the way customers interact with brands and make purchases, enhancing engagement and convenience. Here's how…

Personal Data Privacy and Customer Experience: Balancing Customization and Consent
Balancing personal data privacy and customer experience is a critical challenge for businesses in the digital age. While customization can enhance the customer experience, it must be done in…

Customer Data Platforms (CDPs): Unlocking Insights for Enhanced Customer Understanding
Customer Data Platforms (CDPs) play a crucial role in unlocking insights for enhanced customer understanding by aggregating, consolidating, and analyzing customer data from multiple sources. Here's how CDPs help…

Virtual Reality (VR) Shopping Experiences: Redefining Retail in the Digital Age
Virtual Reality (VR) shopping experiences have the potential to redefine retail in the digital age by providing immersive, interactive, and personalized experiences for customers. Here are some ways VR…

Customer Experience Metrics and Measurement: Evolving Approaches for Success
Measuring customer experience is essential for understanding how well a business is meeting the needs of its customers and identifying areas for improvement. However, traditional metrics such as customer…

Digital Accessibility: Ensuring Inclusive Customer Experiences for All Users
Digital accessibility involves designing and developing digital products, platforms, and content in a way that ensures equal access and usability for all users, including those with disabilities. Ensuring inclusive…

Community-Centric Customer Engagement: Building Loyalty Through Online Communities
Community-centric customer engagement involves building and nurturing online communities to foster brand loyalty, advocacy, and long-term relationships with customers. Here's how businesses can leverage online…

Conversational AI: Revolutionizing Customer Service and Support Interactions
Conversational AI is revolutionizing customer service and support interactions by providing efficient, personalized, and scalable solutions for businesses. Here's how conversational AI is transforming customer…

Emotional Intelligence in Customer Experience: Understanding and Responding to Customer Emotions
Emotional intelligence in customer experience involves understanding and responding to customer emotions effectively to build stronger relationships, foster loyalty, and drive satisfaction. Here's how businesses…

Data-Driven CX Design: Leveraging Analytics to Optimize Customer Journey Mapping
Data-driven customer experience (CX) design involves leveraging analytics and insights to optimize customer journey mapping and enhance the overall customer experience. Here's how businesses can…

Eco-Friendly CX: Aligning Sustainability Efforts with Customer Experience Strategies
Aligning sustainability efforts with customer experience (CX) strategies involves integrating eco-friendly practices and initiatives into the customer journey to enhance environmental responsibility and customer satisfaction.…

CX Metrics and Measurement: Evaluating and Improving Customer Experience Performance
Evaluating and improving customer experience (CX) performance requires the use of key metrics and measurements to assess various aspects of the customer journey and identify…

Human-Centered Design Thinking in CX: Putting Customers at the Heart of Innovation
Human-centered design thinking in customer experience (CX) involves prioritizing the needs, preferences, and experiences of customers throughout the innovation and design process. By putting customers…

Proactive Customer Service: Anticipating Needs and Resolving Issues Before They Arise
Proactive customer service involves anticipating customer needs and resolving issues before they arise, enhancing satisfaction and loyalty. Here's how businesses can implement proactive customer service…
Customer Data Platforms (CDPs): Unlocking Insights for Enhanced Customer Understanding
Customer Data Platforms (CDPs) play a crucial role in unlocking insights for enhanced customer understanding by aggregating, consolidating, and analyzing customer data from multiple sources.…

Omnichannel Integration: Creating Seamless Customer Journeys Across Platforms
Omnichannel integration involves creating seamless and cohesive customer journeys across multiple channels and touchpoints, including physical stores, websites, mobile apps, social media platforms, and customer…

The Role of Augmented Reality in Enhancing In-Store and Online Shopping Experiences
Augmented Reality (AR) technology is revolutionizing both in-store and online shopping experiences by providing immersive, interactive, and personalized experiences for customers. Here's how AR enhances…







Autonomous Driving Revolution: Advancements and Challenges
The autonomous driving revolution represents a paradigm shift in transportation,…

Innovations In The Automotive Industry
Information-oriented technologies play a key role shortly in the automobile industry, according to a comprehensive analysis of industry trends to expect forward to in 2021. At…
AI-Driven Vehicle Intelligence: Transforming the Driving Experience
AI-driven vehicle intelligence is revolutionizing the driving experience by leveraging artificial intelligence (AI) algorithms to enhance safety, efficiency, and convenience. Here's how AI-driven vehicle intelligence is…

Connected Car Ecosystems: Enhancing Safety and Convenience
The concept of connected car ecosystems revolves around integrating vehicles with the broader digital environment, including infrastructure, other vehicles, and external services. This integration offers a…

Vehicular Biometrics: Enhancing Security and Personalization in Automotive Systems
Vehicular biometrics involves the integration of biometric authentication and identification technologies into automotive systems to enhance security, safety, and personalization. Here's how vehicular biometrics is enhancing…

Hydrogen Fuel Cell Vehicles: Progress and Prospects
Hydrogen fuel cell vehicles (FCVs) have made significant progress in recent years, and they hold promising prospects for the automotive industry. Here's an overview of their…

Electric Vehicles 2.0: The Next Phase of EV Innovation
Electric Vehicles (EVs) have experienced remarkable growth and development since their inception. However, "Electric Vehicles 2.0" represents the next phase of innovation in this industry, characterized…

Technologies Used In Automobiles
Electronic technology in cars is becoming as crucial as what is under the hood these days. From security and safety to communication and connectivity these strategies…

Sustainable Materials in Automotive Manufacturing: Trends and Innovations
Sustainable materials in automotive manufacturing have become increasingly important as the industry seeks to reduce its environmental footprint and meet regulatory requirements. Here are some trends…

Augmented Reality in Automotive: Immersive Technologies for Enhanced Navigation and Driving Assistance
Augmented Reality (AR) is poised to revolutionize the automotive industry by offering immersive technologies for enhanced navigation and driving assistance. Here's how AR is transforming the…
5G Connectivity in Cars: Accelerating Data Transfer and Vehicular Communication
5G connectivity in cars represents a significant leap forward in automotive technology, offering faster data transfer speeds, lower latency, and enhanced vehicular communication capabilities. Here's how…

Next-Generation Batteries: Powering the Future of Automotive Electrification
Next-generation batteries are poised to play a pivotal role in powering the future of automotive electrification, offering improvements in energy density, charging speed, lifespan, and safety.…
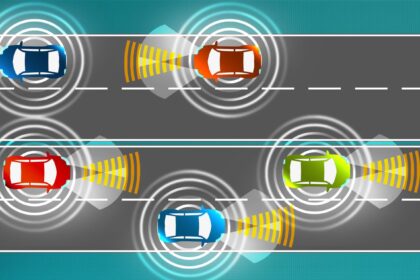
The Role of LiDAR and Radar in Autonomous Driving: Sensing the Road Ahead
LiDAR (Light Detection and Ranging) and radar are essential sensor technologies used in autonomous driving systems to perceive the environment and enable safe navigation. They…

Autonomous Driving: Advancements in Self-Driving Cars and Safety Features
Autonomous driving, also known as self-driving cars or autonomous vehicles (AVs), is a rapidly evolving technology that has the potential to transform the transportation industry.…

The Future of Automotive Technology: Innovations Driving the Industry Forward
image Credit: Guardian Safe and Vault The automotive industry is experiencing rapid advancements driven by emerging technologies that are shaping the future of transportation. Here…

Automotive Technology For Connectivity
Automobile technicians examine, diagnose, and repair mechanical, electronic systems, and electrical as well as components of automobiles. They may specialize in a particular manufacturer's automobiles,…

How technology aids growth of automotive industry
Any significant technological innovation in the automobile industry may be linked back to automobiles technology research. Automatic windows, adaptive cruise control, electronic ignition, and more…

Augmented Reality in Automotive: Enhancing Navigation and Driver Assistance
Augmented Reality (AR) technology is making significant strides in the automotive industry, particularly in enhancing navigation systems and driver assistance features. By overlaying virtual information…
Electric Vehicles (EVs) and the Future of Sustainable Transportation
Electric Vehicles (EVs) play a vital role in the future of sustainable transportation. As the world seeks to reduce greenhouse gas emissions and mitigate the…

Artificial Intelligence in Automotive: Enhancing Driver Assistance and Personalization
Artificial Intelligence (AI) is playing a significant role in the automotive industry, particularly in the development of advanced driver assistance systems (ADAS) and personalized driving…

Automobile industry and the technologies involved
Automotive technicians are in high demand. The automotive, as well as maintenance industries, are likely to develop in the next years. Adding technical expertise to…

5G and Vehicle Connectivity: Enabling High-Speed Communication and Updates
The advent of 5G technology is poised to transform vehicle connectivity by enabling high-speed communication and updates. With its faster data transmission, lower latency, and…

Cybersecurity in Connected Cars: Protecting Against Vehicle Hacking
As vehicles become more connected and autonomous, ensuring robust cybersecurity measures is crucial to protect against potential vehicle hacking threats. Connected cars rely on various…

Advanced Driver-Assistance Systems (ADAS): A Pathway to Autonomous Vehicles
Advanced Driver-Assistance Systems (ADAS) serve as a crucial stepping stone on the pathway towards fully autonomous vehicles. ADAS technologies integrate sensors, AI algorithms, and connectivity…




















Virtual Reality in the Classroom: Immersive Experiences and Simulations
Virtual Reality (VR) in the classroom is transforming traditional education by providing immersive experiences and simulations that enhance learning. By leveraging VR technology, students can…

Navigating the Educational Landscape: Addressing Today’s Major Challenges
There is a saying that “education is the only weapon that can change the world”. There are various sectors operating all across the world and each of them are working on various dimensions, but the…
The Future of Education Technology: Transforming Learning Experiences
The future of education technology (EdTech) holds immense potential for transforming learning experiences and shaping the future of education. As technology continues to advance, several key trends and innovations are expected to have a significant…

Technology reshaping the world of education
Technology is transforming education, changing how, when, and where students learn and empower them at every stage of their journey. With the ultimate aim to personalize the learning process, the technology empowers students by giving…

Tech-Enabled Learning: Maximizing Educational Impact Through Technology
Technology is revolutionizing the complete world in a better way. It has transformed education also, by empowering it by giving them the ownership of how they learn and making education relevant to their digital lives.…

Gamification of Education: Engaging and Motivating Students through Games
Gamification of education refers to the integration of game elements and mechanics into the learning process to engage and motivate students. By applying game design principles, educators can make learning more enjoyable, interactive, and immersive.…

Tips for developing an inclusive education system
In today’s era, where everyone is deeming for human rights equality are highly working for the equality of genders, cast, creed, and other races. “What about the equality of differently abled folks?” Don’t they have…

Recent trends of education sector in 2020
From the digitized educational campuses till digital library, today’s teachers are using latest technologies to bring a revolution in education sector and change the latest teaching methodologies. This era is witnessing a new phase where…

Open Educational Resources (OER): Accessible and Free Learning Materials
Open Educational Resources (OER) are educational materials that are freely available for anyone to use, modify, and share. These resources include textbooks, lecture notes, course materials, videos, simulations, quizzes, and other learning resources that are…

Learning Management Systems (LMS): Centralized Platforms for Course Delivery
Learning Management Systems (LMS) are centralized platforms that provide educational institutions with a comprehensive solution for course delivery, management, and administration. LMS platforms offer a…

STEM Education and Robotics: Building Future-ready Skills
STEM (Science, Technology, Engineering, and Mathematics) education plays a crucial role in preparing students for the challenges and opportunities of the future. Integrating robotics into…

Internet of Things (IoT) in Education: Smart Classrooms and Campus Management
The Internet of Things (IoT) is revolutionizing education by transforming classrooms and campus management into smart and connected environments. IoT technology in education enables the…

Cloud Computing in Education: Collaborative Learning and Data Storage
Cloud computing is revolutionizing the field of education by providing scalable, flexible, and accessible solutions for collaborative learning, data storage, and educational resources. Cloud computing…

Augmented Reality in Education: Enhancing Visualization and Interactive Learning
Augmented Reality (AR) is a technology that overlays digital information and virtual objects onto the real world, enhancing the learning experience by merging the physical…

Mobile Learning: Empowering Education on the Go
Mobile learning, also known as m-learning, refers to the use of mobile devices and technologies to facilitate learning anytime and anywhere. With the widespread availability…

Artificial Intelligence in Education: Personalized Learning and Intelligent Tutoring
Artificial Intelligence (AI) is transforming the field of education by enabling personalized learning experiences and intelligent tutoring systems. These applications of AI in education leverage…
Data Analytics in Education: Insights for Personalized Instruction and Performance Tracking
Data analytics in education is transforming the way we understand and improve teaching and learning processes. By leveraging data analytics techniques, educational institutions can gain…

Adaptive Learning Platforms: Customized Instruction and Assessment
Adaptive learning platforms are educational tools that leverage technology and data to provide customized instruction and assessment tailored to individual learners. These platforms use artificial…






Robotics in Surgery: Advancements in Minimally Invasive Procedures
Robotics in surgery has revolutionized the field by enabling advancements in minimally invasive procedures. Minimally invasive surgery (MIS), also known as robotic-assisted surgery or robot-assisted…

Medical sector to witness a great change in the upcoming decade
A study conducted over the medical sector depicts that a dynamic transformation is about to witness. Healthcare technologies are going to revolutionize the medical sector, such as artificial intelligence, big…

Artificial Intelligence in Medicine: Revolutionizing Diagnosis and Treatment
Artificial Intelligence (AI) has emerged as a transformative technology in the field of medicine, revolutionizing diagnosis and treatment processes. By leveraging vast amounts of medical data, advanced algorithms, and machine…

To persuade physicians to trust remote health monitoring programs
COVID-19 has accelerated the implementation of telehealth as well as remote patient monitoring around the world. This has given health systems the potential to digitally overhaul their patient care approach.…
The Future of Medical Technology: Transforming Healthcare Delivery
The future of medical technology holds great potential for transforming healthcare delivery and improving patient outcomes. Advancements in various fields, including robotics, artificial intelligence (AI), genomics, telemedicine, and nanotechnology, are…

Cyber-attacks on supply chain management during vaccine delivery
Cyber-attacks with a specific target- There is more to this issue than meets the eye. When considering the complete supply chain, one must consider transportation businesses, manufacturers, distributors, and R&D…

How might health IT systems be optimized for immunization campaigns?
The COVID-19 immunization program could become a game-changer for healthcare businesses if the correct technology applications are used. COVID-19 vaccination campaigns, on the other hand, are being prepared in partnership…
Bioprinting and Organ Transplantation: Overcoming Organ Shortage
Bioprinting is an innovative technology that has the potential to overcome the shortage of organs available for transplantation by creating functional, patient-specific organs and tissues. Bioprinting combines 3D printing techniques…
Organization and clinical hurdles during vaccination campaigns
The global rollout of vaccines provides promise, but we must equally recognize the enormous hurdles of distributing and administering vaccinations at scale. The logistical difficulties are well chronicled, but cyber…

Rethinking healthcare services with AI-enabled physicians
While many physicians have been cautious about artificial intelligence in clinical settings in the past, in today's fast-changing healthcare sector, many are considering how AI may enhance the quality of…

Virtual Reality in Medical Training: Simulating Surgical Procedures and Education
Virtual Reality (VR) is playing an increasingly significant role in medical training by providing immersive and realistic simulations of surgical procedures and educational experiences. VR…

Point-of-Care Testing: Portable Devices for Rapid Diagnosis
Point-of-care testing (POCT) refers to diagnostic tests performed at or near the site of patient care, providing rapid results that can aid in immediate clinical…

Regenerative Medicine: Harnessing Stem Cells for Tissue Repair and Regrowth
Regenerative medicine is an innovative field that aims to restore or replace damaged tissues and organs by harnessing the power of stem cells and other…
Smart Pills and Digital Therapeutics: Innovations in Medication Adherence
Smart pills and digital therapeutics are two innovative approaches that are transforming medication adherence, improving patient outcomes, and enhancing healthcare delivery. Let's take a closer…
Medical Imaging Advancements: High-resolution Scans and AI-assisted Diagnostics
Medical imaging has witnessed significant advancements, driven by technological innovations and the integration of artificial intelligence (AI). These advancements have led to high-resolution scans and…
Gene Editing and CRISPR Technology: Transforming Genetic Therapies
Gene editing, particularly through the revolutionary CRISPR-Cas9 technology, is transforming the field of genetic therapies by offering precise and efficient tools to modify the DNA…

Medical Drones: Delivering Supplies and Emergency Care in Remote Areas
Medical drones have emerged as a promising technology for delivering medical supplies and emergency care to remote and inaccessible areas. These unmanned aerial vehicles (UAVs)…

Nanotechnology in Healthcare: Targeted Drug Delivery and Disease Detection
Nanotechnology has revolutionized the field of healthcare by enabling precise and targeted drug delivery systems and advanced disease detection methods. By manipulating materials at the…

Brain-Computer Interfaces: Restoring Functionality and Treating Neurological Disorders
Brain-computer interfaces (BCIs) are innovative technologies that establish a direct communication pathway between the brain and external devices or computer systems. BCIs hold great potential…

Biosensors and Wearable Devices: Monitoring Health and Vital Signs
Biosensors and wearable devices are playing a significant role in monitoring health and vital signs, allowing individuals to track and manage their well-being in real-time.…







Artificial Intelligence in Law: Transforming Legal Research and Document Analysis
Artificial intelligence (AI) is transforming the field of law by automating and enhancing various legal processes. In particular, AI is revolutionizing legal research and document…

Blockchain in Legal Contracts: Enhancing Security and Efficiency
Blockchain technology is transforming the way legal contracts are created, executed, and enforced by enhancing security, transparency, and efficiency. Here's…

Boost up law firms with virtual assistants
There are niche disciplines that legal areas are split into that needs expertise. It can be an enterprise or an…
Online Dispute Resolution: Transforming Alternative Dispute Resolution (ADR)
Online Dispute Resolution (ODR) is a rapidly evolving field that utilizes technology to resolve disputes efficiently and effectively through online…

Legal Chatbots and Virtual Assistants: Automating Client Interactions and Support
Legal chatbots and virtual assistants are emerging technologies in the legal industry that automate client interactions and provide support. These…

Technologies that makes legal job easier
Law is dynamical so is the technology. Legal technology expedites the lawyers in different tasks. No machine can do the…

The exigency for legal tech
The world is confronting disruptions that nobody set it up for. Notwithstanding, one thing that has stayed consistent is the…

Cloud Computing in Legal Practice: Collaboration and Data Storage
Cloud computing is revolutionizing the legal practice by enabling seamless collaboration, efficient data storage, and flexible access to information. Here's…

Data Privacy and Compliance in the Digital Age: Challenges and Solutions
In the digital age, data privacy and compliance have become critical concerns for individuals, organizations, and governments. The widespread collection,…

Digital Evidence and E-Discovery: Managing Big Data in Litigation
In the digital age, the volume and complexity of electronic data have increased exponentially, presenting unique challenges in the context…

Predictive Analytics in Legal Decision-making: Improving Case Outcomes
Predictive analytics is a technology that utilizes data, statistical algorithms, and machine learning techniques to analyze past and current data…

Smart Contracts: Streamlining Contract Management and Execution
Smart contracts are computer programs that automatically execute predefined actions or conditions based on the terms and conditions written into…

Conveyance deed – A legal document is important; know why?
There are several different property documents or deeds when you are buying or selling properties. The real estate deals are never possible without the presence…

All you need to know about immigration services
Procuring immigration visas vary from country to country, as the legal formalities of immigration services are never the same in each of these countries. There…

Legal Research Platforms: Accessing Comprehensive and Relevant Information
Legal research platforms play a crucial role in the legal industry by providing access to comprehensive and relevant information for legal professionals. These platforms leverage…

Cybersecurity in the Legal Industry: Protecting Sensitive Client Data
Cybersecurity is a critical concern for the legal industry, as law firms and legal professionals handle vast amounts of sensitive client data. Protecting this data…

Legal Document Automation: Streamlining Document Creation and Review
Legal document automation refers to the use of technology to streamline and automate the creation, drafting, and review of legal documents. It involves leveraging software…

Technology-Assisted Review (TAR) in e-Discovery: Improving Efficiency and Accuracy
Technology-Assisted Review (TAR), also known as predictive coding or machine learning-assisted review, is a powerful tool in the field of e-discovery that utilizes advanced algorithms…

Virtual Reality in Courtrooms: Enhancing Visual Presentations and Jury Understanding
Virtual Reality (VR) is being increasingly explored and implemented in courtrooms to enhance visual presentations and improve the understanding of evidence by juries. Here's how…

Demystification of legal tech
Lawyers can rationalize their law practices by coalescing tools of legal research and practice management in their law operations. Even a lawyer who still has…

Legal Research and its benefits
Every lawsuit, court appeal, criminal cases, and legal procedures need a certain amount of legal research. Legal research helps in determining the current legal scenarios…

Most crucial legal technology development in past few years
Legal sector is one of those sectors which are known to everyone but hardly folks enter in this sector to work with. If you count…

What is Legal Tech & How it is changing Business Sectors?
Legal sector has a great importance in every business sector but earlier it was a bit hectic and time consuming task. An integration of technology…

The step of legal sector towards technology
There are a number of business sectors operating in the present era and almost among those are rigidly tied with technologies in some or other…






The Future of Government Technology: Transforming Public Services
The future of government technology holds tremendous potential for transforming public services and enhancing citizen experiences. As technology continues to advance, governments around the world…

Cloud Computing in Government: Enabling Scalability and Cost Savings
Cloud computing has become an integral part of modern government operations, offering numerous benefits in terms of scalability, cost savings, and efficiency. Here are some key advantages…
Blockchain in Government: Improving Transparency and Efficiency
Blockchain technology has the potential to transform the way governments operate by enhancing transparency, improving efficiency, and increasing trust in public services. Blockchain is a decentralized and…

Citizen Engagement and Participatory Governance through Digital Platforms
Citizen engagement and participatory governance are crucial elements of modern democracies. Digital platforms have revolutionized the way governments interact with citizens, enabling greater participation, collaboration, and transparency…
E-Government and Digital Transformation: Improving Access and Service Delivery
E-government and digital transformation initiatives have revolutionized the way governments interact with citizens, businesses, and other stakeholders. By leveraging digital technologies, governments aim to improve access to…

Privacy and Data Protection in the Digital Era: Balancing Security and Privacy Rights
In the digital era, privacy and data protection have become critical concerns as individuals and organizations increasingly rely on digital technologies and share personal information online. Balancing…

Emerging Technologies in Public Safety: Enhancing Emergency Response and Disaster Management
Emerging technologies are playing a crucial role in enhancing public safety and improving emergency response and disaster management. These technologies leverage advancements in areas such as artificial…

Artificial Intelligence in Public Administration: Streamlining Decision-making and Service Delivery
Artificial Intelligence (AI) is revolutionizing public administration by streamlining decision-making processes and improving service delivery to citizens. AI technologies can automate tasks, analyze vast amounts of data,…

Data Analytics for Evidence-based Policy-making and Decision-making
Data analytics plays a crucial role in evidence-based policy-making and decision-making by providing insights and informing strategies based on empirical evidence rather than intuition or assumptions. Here's…

Internet of Things (IoT) for Smart Governance: Enhancing Efficiency and Connectivity
The Internet of Things (IoT) refers to the network of interconnected devices, sensors, and systems that communicate and exchange data over the internet. When applied to smart…

Cybersecurity in Government: Protecting Critical Infrastructure and Data
Cybersecurity in government plays a critical role in protecting essential infrastructure, sensitive data, and ensuring the continuity of public services. As governments increasingly rely on digital systems…

Modernization by technology
An efficacious government is a cornerstone for developing the country. Also, upheave in citizens expectation has made the government perform well. The potential to meet…

Digital Identity and Authentication: Enhancing Security in Government Services
Digital identity and authentication play a crucial role in enhancing security and trust in government services. As governments increasingly transition towards digital platforms and online…

Regulatory Sandboxes: Fostering Innovation in Government Regulations
Regulatory sandboxes are frameworks or programs that allow businesses, startups, and innovators to test new products, services, or business models in a controlled and supervised…

Open Government Data: Empowering Citizens and Driving Innovation
Open Government Data (OGD) refers to the concept of making government data freely available to the public in a machine-readable format. By opening up government…

Strategies to Improve Public Sector Labour Productivity
Labour productive is an essential element for any organization to perform well and achieve intended goal. To keep your organizational working procedure effective and accurate,…

Government healthcare programs: A step towards a healthier tomorrow
Healthcare is one of the most crucial sectors used by folks regardless of their bank balance, region, or any other race. The facilities provided by…

Major challenges faced by army
Army constitutes a major part of government sector has also plays a crucial role in saving an entire country by protecting its borders from the…

Efficient government technologies
We are in the era where a blanket of technologies is being unfolded, that is being used in different ways in daily lives, on which…

Top GovTech Trends Revealed for 2021
The year 2021 has come up with a wide array of changes for the entire world. The government is also moving up front to bring…

Communicating legit information in this pandemic
The COVID-19 (coronavirus) is plausibly the pandemic that has worsen the situation in the whole world. Since its inception to date, there have been various…

Technology facilitating low-touch economy
Many businesses and workers are initiating new ways in their jobs to suit the low-touch economy. The industries were forced to rapidly adjust to newly…

Protecting sensitive data while working remotely
The past year showed some tempestuousness for consumers and businesses. This crisis has compelled numerous companies in the world to relocate from office to remote…

Smart Cities: Harnessing Technology for Sustainable Urban Development
Smart cities are urban areas that leverage technology and data to enhance the quality of life for residents, improve sustainability, and optimize resource management. These…



















Factors driving telemedicine towards growth
A number of aspects of real technological world are changing our day to day life and medical sector is undergoing through a tremendous change making…

Telemedicine and Rehabilitation: Virtual Therapy for Physical and Occupational Health
Telemedicine has emerged as a valuable tool in the field of rehabilitation, offering virtual therapy for physical and occupational health. Here's how telemedicine enhances rehabilitation services: Remote Consultations: Telemedicine enables…
The Future of Telemedicine: Transforming Healthcare Delivery
The future of telemedicine holds great potential to transform healthcare delivery and improve access to medical services. Telemedicine, also known as telehealth, refers to the use of technology to provide…

The Role of Wearable Devices in Telemedicine: Monitoring Health from Anywhere
Wearable devices play a significant role in telemedicine by enabling the remote monitoring of patients' health from anywhere. These devices, typically worn on the body or incorporated into clothing, collect…

Telemedicine Integration in Electronic Health Records (EHR): Streamlining Care Coordination
The integration of telemedicine with Electronic Health Records (EHR) systems has proven to be valuable in streamlining care coordination and improving the efficiency of healthcare delivery. Here's how the integration…

Telemedicine and Emergency Medicine: Enhancing Critical Care in Remote Settings
Telemedicine plays a crucial role in enhancing critical care in remote settings, particularly in emergency medicine. Here are some ways in which telemedicine enhances emergency care in remote areas: Remote…

Telemedicine and Home Health Monitoring: Enabling Aging in Place
Telemedicine, coupled with home health monitoring, plays a crucial role in enabling aging in place—the ability for older adults to live independently in their own homes while receiving necessary healthcare…

The Future of Telemedicine Regulation and Reimbursement: Policy Considerations
The future of telemedicine regulation and reimbursement is a crucial area of focus as telemedicine continues to evolve and expand. Several policy considerations are important for ensuring the effective implementation…

Telemedicine and Disaster Response: Providing Medical Care in Crisis Situations
Telemedicine plays a critical role in disaster response by providing remote medical care and support in crisis situations. Here's how telemedicine enhances disaster response efforts: Remote Medical Triage: Telemedicine enables…

Telemedicine for Aging Populations: Supporting Independent Living and Elderly Care
Telemedicine plays a significant role in supporting independent living and improving healthcare for aging populations. Here's how telemedicine benefits older adults and enhances elderly care: Remote Consultations: Telemedicine enables older…

Teleophthalmology: Remote Eye Care and Vision Services
Teleophthalmology is a branch of telemedicine that focuses on providing remote eye care and vision services. It utilizes telecommunication technology to facilitate virtual consultations, diagnosis, and management of eye conditions.…

Telemedicine and Pediatric Healthcare: Enabling Remote Pediatric Consultations
Telemedicine plays a vital role in pediatric healthcare by enabling remote consultations, improving access to specialized care, and facilitating convenient healthcare delivery for children and their families. Here are some…

Benefits & Challenges of Telemedicine
A number of changes have witnessed by the world in the recent years and the best achievement of technological advancement has transformed the way of thinking of society. Today, telemedicine…

Applications of telemedicine
In recent days, telemedicine has gained popularity among common folks. Now people are opting telemedicine options instead of physically visiting the healthcare specialist. In this…

Impact of COVID-19 on Telemedicine growth
COVID-19 pandemic is disrupting human life and is a biggest threat for humans restricting folks to go to a public place and also social gatherings.…

Telemedicine Platforms: Innovations in Virtual Care Delivery
Telemedicine platforms have revolutionized the way healthcare is delivered by enabling remote consultations, virtual care, and enhancing patient-provider communication. Here are some key innovations and…

Telemedicine: New face of Medical Sector
The present scenario, when folk is deprived of every facility, being deprived from the medical facilities is one of the greatest threat to the human…
Benefits & Challenges of Telemedicine
A number of changes have witnessed by the world in the recent years and the best achievement of technological advancement has transformed the way of…

Get to know all about telemedicine
Each phase of development comes up with a positive and a negative side, so as telemedicine also. Emergence of telemedicine has brought a great change…

Telepsychiatry: Bridging the Gap in Mental Health Care
Telepsychiatry, the delivery of mental health care services through telemedicine, is playing a crucial role in bridging the gap in mental health care by improving…

Telemedicine in Rural Areas: Overcoming Healthcare Access Barriers
Telemedicine has emerged as a powerful solution for overcoming healthcare access barriers in rural areas. Here are some ways in which telemedicine helps improve healthcare…

Telemedicine and Chronic Disease Management: Improving Patient Outcomes
Telemedicine has emerged as a valuable tool in the management of chronic diseases, offering convenient access to healthcare services and improving patient outcomes. Here's how…

Telehealth Technologies: Advancements in Remote Patient Monitoring
Telehealth technologies have made significant advancements in remote patient monitoring, enabling healthcare providers to monitor patients' health conditions and vital signs remotely. Here are some…

Virtual Doctor Visits: The Rise of Remote Medical Consultations
Virtual doctor visits, also known as telemedicine or telehealth, have experienced a significant rise in popularity, especially in recent years. They involve remote medical consultations…
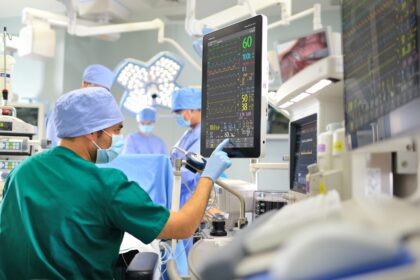
Factors driving telemedicine towards growth
A number of aspects of real technological world are changing our day to day life and medical sector is undergoing through a tremendous change making…
The Future of Telemedicine: Transforming Healthcare Delivery
The future of telemedicine holds great potential to transform healthcare delivery and improve access to medical services. Telemedicine, also known as telehealth, refers to the…

Artificial Intelligence in Telemedicine: Enhancing Diagnosis and Treatment
Artificial intelligence (AI) has the potential to revolutionize telemedicine by enhancing the accuracy and efficiency of diagnosis and treatment. Here's how AI is being used…






Artificial Intelligence (AI) in Smart Cities: Enabling Predictive Maintenance and Automated Services
Artificial Intelligence (AI) plays a crucial role in smart cities by enabling predictive maintenance and automated services, leading to improved efficiency, cost savings, and enhanced quality of life. Here are key aspects of AI in smart cities: Predictive Maintenance: AI algorithms analyze data from various…

Smart Waste Management: Optimizing Collection and Recycling Processes
Smart waste management is an innovative approach that leverages technology to optimize waste collection and recycling processes in cities and communities. By integrating various smart solutions and data-driven insights, smart waste management systems aim to…
Smart Transportation: Revolutionizing Mobility and Reducing Traffic Congestion
Smart transportation is revolutionizing mobility by utilizing technology and data-driven solutions to improve transportation systems, reduce traffic congestion, and enhance overall efficiency. It encompasses a range of innovative approaches that leverage connectivity, real-time data, and…

Intelligent Public Safety Systems in Smart Cities: Enhancing Emergency Response
Intelligent public safety systems play a crucial role in smart cities by enhancing emergency response capabilities and improving overall public safety. Here are key aspects of intelligent public safety systems in smart cities: Real-time Monitoring…
Smart Water Management: Improving Efficiency and Conservation in Cities
Smart water management plays a crucial role in improving efficiency and conservation in cities by leveraging technology and data-driven approaches. Here are key aspects of smart water management in cities: Water Infrastructure Monitoring: Smart water…

The Role of Blockchain in Smart Cities: Enhancing Security and Trust
Blockchain technology has the potential to play a significant role in enhancing security and trust in smart cities. By its decentralized and immutable nature, blockchain can provide several benefits to smart city ecosystems. Here's how…
Digital Governance and Citizen Engagement in Smart Cities: Enhancing Participation and Transparency
In smart cities, digital governance and citizen engagement play a vital role in promoting participation, transparency, and inclusive decision-making processes. By leveraging technology and data-driven approaches, smart cities can enhance citizen involvement in shaping urban…

Cybersecurity in Smart Cities: Safeguarding Critical Infrastructure and Personal Data
Cybersecurity is a critical aspect of smart cities as the increased connectivity and digitization of infrastructure and services also introduce new vulnerabilities and risks. Safeguarding critical infrastructure and personal data is essential to ensure the…

Data Analytics in Smart Cities: Leveraging Insights for Efficient Resource Allocation
Data analytics plays a critical role in smart cities by leveraging insights from vast amounts of data to facilitate efficient resource allocation and improve urban planning. Here are key aspects of using data analytics in…

Inclusive and Accessible Smart Cities: Bridging the Digital Divide
Inclusive and accessible smart cities aim to bridge the digital divide and ensure that the benefits of technology and connectivity are accessible to all citizens, regardless of their socioeconomic status, abilities, or location. Here are…

Smart Health Services: Innovations in Healthcare Delivery and Telemedicine
Smart health services are transforming the way healthcare is delivered by leveraging technology and innovations to improve access, efficiency, and patient outcomes. These services encompass a range of solutions, including telemedicine, remote patient monitoring, electronic…

Urban Agriculture and Smart Cities: Embracing Sustainable Food Production
Urban agriculture is gaining momentum as a sustainable solution to enhance food production and promote self-sufficiency in smart cities. By integrating smart technologies and innovative farming methods, urban agriculture transforms underutilized spaces into productive areas…

Ethical Considerations in Technology: CIOs’ Responsibility in Building Responsible and Inclusive Systems
As technology continues to shape our society, CIOs have a significant responsibility to ensure ethical considerations are integrated into the development and deployment of technology systems. Here are…
Digital Governance and Citizen Engagement in Smart Cities: Enhancing Participation and Transparency
In smart cities, digital governance and citizen engagement play a vital role in promoting participation, transparency, and inclusive decision-making processes. By leveraging technology and data-driven approaches, smart cities…

The first pillar of a smart city – Institutional development
The concept of the smart city differs from person to person. For some, a city flourishes with its institutional growth, and for some, an excellent infrastructural development is…

The second pillar of a smart city – Development of physical infrastructure
When all focus is on building your smart city, how can we negate the role of the development of physical infrastructure? The purpose of physical infrastructure towards the…

Smart Tourism: Enhancing Visitor Experiences and Sustainable Travel
Smart tourism leverages technology and data to enhance visitor experiences, promote sustainable travel practices, and create a more connected and personalized tourism ecosystem. Here are key aspects of…

Moscow introduces blockchain e-voting to overhaul smart-city plans
The Moscow local government is looking to implement an often-discussed idea: an e-voting system built on blockchain. While many issues have been raised (particularly in Ireland) surrounding e-voting…

The third pillar of a smart city – Development of social infrastructure
Imagine a city has everything that it takes to be called as a smart city; the basic amenities, physical infrastructure, well-planned governance institution and all. Can the city…

Art and Culture in Smart Cities: Incorporating Creativity and Community Engagement
Art and culture play a vital role in smart cities by fostering creativity, community engagement, and enhancing the overall quality of life. Here are key aspects of incorporating…
The Future of Smart Cities: Transforming Urban Living with Technology
The future of smart cities holds great potential for transforming urban living through the integration of technology and data-driven solutions. Smart cities aim to enhance the quality of…

Sustainable Energy Solutions in Smart Cities: Harnessing Renewable Resources
Image Credit: ecolife.zone In the context of smart cities, sustainable energy solutions play a crucial role in reducing carbon emissions, promoting environmental sustainability, and ensuring a reliable energy…

IoT and Connectivity in Smart Cities: Building the Foundation for Digital Infrastructure
IoT (Internet of Things) and connectivity form the foundation of digital infrastructure in smart cities. They enable the seamless flow of data and information among various devices, systems,…

Resilient Cities: Building Disaster Preparedness and Climate Change Adaptation
Resilient cities are proactive in building disaster preparedness and adapting to the challenges posed by climate change. They prioritize strategies and initiatives that enhance their ability to withstand…

Smart City and its growing impact
The idea of a smart city has become extremely important when it comes to the context of defining the strength, performance, facility, demography and urban economy. How a…

Cognitive Analytics: Advancements in Emotion, Sentiment, and Image Analysis
Cognitive analytics is an advanced form of data analytics that focuses on analyzing and interpreting unstructured data, such as emotions, sentiments, and images. It goes…

Prescriptive Analytics: Optimizing Decision-Making with Data-Driven Recommendations
Prescriptive analytics is a form of advanced analytics that combines historical data, real-time data, and machine learning algorithms to generate data-driven recommendations for decision-making. Unlike descriptive and predictive analytics, which focus on analyzing past and present…

Data Quality and Data Governance: Ensuring Accuracy and Reliability in Analytics
Data quality and data governance are critical components of any successful data analytics strategy. Data quality refers to the accuracy, completeness, consistency, and timeliness of data, while data governance refers to the policies, procedures, and standards…
Explainable AI in Data Analytics: Building Trust and Transparency in Predictive Models
Explainable AI refers to the ability to provide understandable explanations for the decisions and predictions made by artificial intelligence (AI) models, particularly in the field of data analytics. As AI models become increasingly complex and powerful,…

Data Analytics and Internet of Things (IoT): Unlocking Insights from Connected Devices
Data analytics and the Internet of Things (IoT) go hand in hand, working together to unlock valuable insights from the vast amount of data generated by connected devices. IoT refers to the network of physical objects…

Data Lakes and Data Warehousing: Evolution and Integration in Modern Analytics
Data lakes and data warehousing are two common approaches to storing and managing large volumes of data for analytics. While both have their strengths and weaknesses, organizations are increasingly looking to integrate these two approaches to…

Graph Analytics: Uncovering Hidden Connections and Relationships in Data
Graph analytics is a method of analyzing data that focuses on the relationships between entities. Graphs, or networks, consist of nodes (representing entities) and edges (representing relationships), and graph analytics is concerned with analyzing the patterns…

Cognitive Analytics: Advancements in Emotion, Sentiment, and Image Analysis
Cognitive analytics is an advanced form of data analytics that focuses on analyzing and interpreting unstructured data, such as emotions, sentiments, and images. It goes beyond traditional analytics by incorporating artificial intelligence (AI) techniques to understand…

Spatial Analytics: Discovering Patterns and Insights in Geographical Data
Spatial analytics is the process of analyzing and interpreting geographic or location-based data to discover patterns, insights, and trends that may not be immediately apparent in traditional tabular or numerical data. It involves the use of…

Data Storytelling: Communicating Insights Effectively through Data Visualization
Data storytelling is the practice of using data visualization techniques to communicate insights and narratives derived from data. It involves transforming raw data into compelling and understandable stories that engage and inform the audience. Effective data…

Data Privacy in the Age of Analytics: Safeguarding Personal Information
In the age of analytics, where data is increasingly collected, analyzed, and utilized, safeguarding personal information and ensuring data privacy is of utmost importance. Here are some key considerations and best practices for safeguarding personal information…

Enhance business profits with Data Analytics
Data analytics examines large amounts of data to understand the hidden patterns, and relations to understand the useful insights. It is possible to analyse data…

Forecast about your business future with Data Analytics
Data Analytics is the process of analysing raw data to find conclusion about the information. In general, data analytics comprises of diverse types of data…

Augmented Analytics: The Future of Data Analysis
Augmented analytics is a technology that uses machine learning and artificial intelligence (AI) algorithms to enhance data analytics processes. By automating parts of the data…

Natural Language Processing (NLP) in Data Analytics: Extracting Insights from Unstructured Text
Natural Language Processing (NLP) plays a crucial role in data analytics by enabling organizations to extract valuable insights from unstructured text data, such as customer…

Data Democratization: Empowering Business Users with Self-Service Analytics
Data democratization is the process of providing access to data and analytics tools to a broader range of users within an organization. This enables business…
Big Data Analytics: Advancements and Challenges in Processing and Analyzing Large Datasets
Big data analytics involves the processing and analysis of large and complex datasets to identify patterns, trends, and insights that can inform decision-making. While big…

Ethical Considerations in Data Analytics: Balancing Innovation and Privacy
Data analytics has the potential to revolutionize industries, improve decision-making, and advance innovation. However, with the vast amounts of data being collected and analyzed, there…

Real-Time Analytics: Harnessing the Power of Streaming Data
Real-time analytics is the process of analyzing and responding to data as it is generated, rather than after the fact. This is made possible by…
Data transformation with Data Analytics
Data analytics refers to the various procedures of deriving valuable insights from data. It involves various methods such as extraction of data and then it's…

Make better business decisions with Data Analytics
Data Analytics is the science of examining raw data to conclude that information. It is the process of applying an algorithmic or mechanical process to…
Data Visualization: Transforming Complex Data into Actionable Insights
Data visualization is the process of presenting complex data in a visual format, such as charts, graphs, maps, or interactive dashboards. It plays a crucial…

Data Analytics Business Decisions Effectively
Imagine you are having the raw information but don't know how to make use of it for the business? Here comes the solution of Data…
Predictive Analytics: Forecasting Trends and Making Data-Driven Decisions
Predictive analytics is a technique that uses historical data, statistical algorithms, and machine learning to forecast future trends, outcomes, or behaviors. By analyzing patterns and…

Big Data Analytics in Manufacturing: Optimizing Operations and Predictive Maintenance
Big data analytics has a significant impact on the manufacturing industry by enabling organizations to optimize operations and implement predictive maintenance strategies. Here's how big…

Big Data and IoT: Challenges and Solutions in Managing Massive Data Streams
The convergence of big data and the Internet of Things (IoT) has led to the generation of massive data streams from interconnected devices and sensors. Managing and…

Big Data in Healthcare: Leveraging Data for Improved Patient Outcomes and Research
Big Data has the potential to revolutionize healthcare by providing insights into patient care and enabling the development of new treatments. Here are some ways that healthcare…

Big Data Visualization: Tackling the Complexity of Visualizing Large and Complex Datasets
Big Data visualization refers to the process of creating visual representations of large and complex datasets to help people understand the data and derive insights from it.…

Data Privacy Laws and Big Data: Compliance Challenges in a Global Landscape
Complying with data privacy laws while utilizing big data in a global landscape presents several challenges due to the varying requirements and regulations across jurisdictions. Here are…
Real-time Big Data Analytics: Challenges and Opportunities for Decision Making
Real-time Big Data analytics refers to the processing and analysis of large volumes of data in real-time or near-real-time to derive insights and make informed decisions. Real-time…

Big Data in Smart Cities: Enhancing Urban Planning and Infrastructure Management
Smart cities are urban areas that use advanced technologies to improve the quality of life for their citizens and enhance sustainability. Big Data analytics plays a crucial…

Scaling Big Data Infrastructure: Overcoming Challenges in Storage and Processing
Scaling Big Data infrastructure can be a daunting task, as it requires overcoming challenges in both storage and processing. Here are some of the challenges and best…

Big Data in Financial Services: Navigating Regulatory Compliance and Risk Management
Big data has had a significant impact on the financial services industry, enabling organizations to derive valuable insights, enhance decision-making processes, and improve customer experiences. However, the…

Big Data and Customer Experience: Challenges in Personalization and Data-driven Insights
Big Data has transformed the way companies approach customer experience by providing insights into customer behavior, preferences, and needs. Here are some of the challenges in personalization…

Big Data Integration: Overcoming Data Silos and Ensuring Data Quality
Big data integration refers to the process of combining and harmonizing data from disparate sources to create a unified and comprehensive view of the data. It involves…

Big Data and Machine Learning: Challenges in Training and Deploying Models at Scale
Big Data and Machine Learning are two closely related technologies that have the potential to transform many industries. However, there are several challenges when it comes to…
Effective uses of Big Data helping various industries to grow further
Data was ever a crucial aspect for every business sectors; either you talk about the present decade or date back to the past or older…

The Future of Big Data: Emerging Trends and Challenges
Big Data has already transformed the way we analyze and make decisions based on vast amounts of data, and its future is only getting brighter.…
In what ways big data abetting the digital transformation?
One of the key factor for digital transformation is the big data. An organisation has huge data which is generated, collected frequently so these organisations…

Ways Big Data is Revolutionizing Business Operations
Big Data refers to the large and complex data sets that can be analyzed to reveal patterns, trends, and associations. In recent years, Big Data…
Ethical Considerations in Big Data Analytics: Privacy, Bias, and Transparency
Big data analytics has the potential to revolutionize industries and provide valuable insights. However, it also raises several ethical considerations that need to be addressed.…
Big Data Ethics: Balancing Data Utilization and Individual Privacy
Big Data ethics refers to the principles and guidelines that govern the collection, use, and management of large and complex datasets. One of the key…

Securing Big Data: Addressing Cybersecurity Challenges in Data-driven Environments
Securing big data in data-driven environments is of paramount importance to protect sensitive information and maintain the integrity of data analytics processes. Here are some…

Big Data and Social Media: Analyzing and Utilizing User-generated Content
Social media platforms generate massive amounts of user-generated content every day, including text, images, videos, and other forms of media. This data presents an opportunity…

Gain Business Enhancements with Big Data
With the requirement of business enhancements along with improved customer experience, every business, governmental institutions have started utilizing the power of Big Data. Big Data…

Data Governance in the Era of Big Data: Challenges and Best Practices
Data governance is the process of managing the availability, usability, integrity, and security of data used in an organization. With the advent of Big Data,…

Big Data Skills Gap: Addressing the Shortage of Data Scientists and Analysts
The shortage of skilled data scientists and analysts is a challenge faced by many organizations due to the increasing demand for big data expertise. Here…

Big data revolutionizing the marketing industry
Big data is a hot topic in the world of marketing. When you talk about marketing, the sector reflects a lot of challenges and fewer…

Fraud detection with big data analysis
World is moving to the digitized platforms and this digital approach is also giving a strong way to the intruders to enter any digital network…

Serverless DevOps Frameworks: Managing Functions as a Service (FaaS) Architectures
Serverless DevOps frameworks are designed to facilitate the development, deployment, and management of applications built on Functions as a Service (FaaS) architectures. These frameworks help…

Event-driven DevOps: Harnessing Event Streaming and Event-Driven Architecture
Event-driven DevOps is an approach that leverages event streaming and event-driven architecture (EDA) to enable organizations to build, deploy, and operate their applications and systems more efficiently.…

The Human Factor in DevOps: Cultivating Collaboration and DevOps Culture
The Human Factor in DevOps refers to the importance of fostering collaboration, communication, and a strong DevOps culture within an organization. While DevOps practices heavily rely on…

Shift-Right Testing in DevOps: Leveraging Feedback Loops for Continuous Improvement
Shift-Right testing is an approach in DevOps that focuses on gathering feedback and insights from production environments to drive continuous improvement in software development and delivery. Unlike…

Infrastructure as Code (IaC) in DevOps: Automating Infrastructure Deployment and Configuration
Infrastructure as Code (IaC) is a practice in DevOps that involves managing and provisioning infrastructure resources using code, typically in a declarative and version-controlled manner. It enables…

Cloud-native DevOps: Building and Managing Applications for Cloud Environments
Cloud-native DevOps is an approach to software development and delivery that combines DevOps principles with cloud-native technologies. It focuses on building and managing applications that are specifically…

Serverless DevOps Frameworks: Managing Functions as a Service (FaaS) Architectures
Serverless DevOps frameworks are designed to facilitate the development, deployment, and management of applications built on Functions as a Service (FaaS) architectures. These frameworks help streamline the…

Site Reliability Engineering (SRE) and DevOps: Achieving High Reliability and Scalability
Site Reliability Engineering (SRE) is an approach to software engineering that emphasizes the reliability and maintainability of systems. It was developed by Google in response to the…

DevOps for Machine Learning: Bridging the Gap between Data Science and Operations
DevOps for machine learning (ML) is an emerging approach that aims to streamline the deployment and management of ML models by integrating ML workflows into DevOps processes.…

The Future of Continuous Integration and Continuous Delivery (CI/CD)
Continuous Integration and Continuous Delivery (CI/CD) is a methodology for delivering software quickly and reliably by automating the build, test, and deployment processes. The future of CI/CD…

Chaos Engineering in DevOps: Simulating Failures to Improve Resilience
Chaos Engineering is a practice in DevOps that involves intentionally injecting failures and disruptions into a system to uncover weaknesses, test resilience, and improve overall system reliability.…

Artificial Intelligence in DevOps: Optimizing Processes and Decision-Making
Artificial Intelligence (AI) is rapidly transforming the way DevOps teams operate by enabling the automation of complex tasks and decision-making processes. AI in DevOps refers…
Yield Significant ROI with DevOps Framework
DevOps is a set of practices that works to automate and integrate the processes between software development and IT teams. The term DevOps was formed…

DevOps Automation: The Future of Continuous Integration and Deployment
DevOps automation is the future of continuous integration and deployment. It is an approach to software development that emphasizes collaboration, communication, and integration between developers…

Yield maximum returns with DevOps
DevOps is the complete set of cultural philosophies, practices, and tools which increase an organization's ability to deliver applications and services at a greater speed.…

Serverless Computing in DevOps: Revolutionizing Application Development and Deployment
Serverless computing, also known as Function as a Service (FaaS), is a cloud computing model that revolutionizes application development and deployment in the field of…

Accelerating teamwork with DevOps
DevOps is the practice of operations and development engineers participating together, right from the stage of design and development process and up to the last…

Get started with DevOps services
As the word defines, DevOps defines a compound of development(Dev) and operations(Ops), DevOps is the process of mixing people, process, and technology to offer value…

Kubernetes and Containerization: Advancements in Orchestrating DevOps Environments
Kubernetes and containerization have brought significant advancements to orchestrating DevOps environments, providing efficient management and scalability for modern application deployment. Here's how Kubernetes and containerization…

DevSecOps: Integrating Security into the DevOps Lifecycle
DevSecOps is the practice of integrating security measures into the DevOps (Development and Operations) process to ensure that security is considered from the start and…

Gain higher quality business developments with DevOps
DevOps is an approach to culture, automation, and platform designed to deliver increased business value. It is possible through fast-paced, iterative IT service delivery. DevOps…

AIOps: The Convergence of AI and DevOps for Intelligent Operations
Image Credit : ClaudeAI.uk AIOps, which stands for Artificial Intelligence for IT Operations, represents the convergence of AI (Artificial Intelligence) and DevOps (Development and Operations) methodologies…

Shift-Left Testing in DevOps: Early and Continuous Quality Assurance
Shift-Left Testing is a testing approach that emphasizes the importance of early and continuous quality assurance in the software development lifecycle. It involves moving testing…

Drone Regulation and Airspace Management: Balancing Safety and Innovation
Drone regulation and airspace management play a crucial role in balancing safety and innovation in the use of unmanned aerial vehicles (UAVs). As drones become more prevalent in various industries and recreational use, it is…

Drone Photography and Videography: Capturing Stunning Aerial Imagery
Drone photography and videography have revolutionized the way we capture stunning aerial imagery, providing unique perspectives and breathtaking views that were once only possible with expensive helicopter or aircraft setups. Drones equipped with high-quality cameras…
Urban Air Mobility: The Future of Personal Transportation with Drones
Urban Air Mobility (UAM) refers to the use of drones or other aerial vehicles for personal transportation within urban areas. It envisions a future where people can travel efficiently and rapidly through the air, bypassing…

Drone Technology for Disaster Response and Emergency Management
Drone technology has emerged as a powerful tool for disaster response and emergency management, offering significant advantages in terms of speed, efficiency, and data collection. Drones, also known as unmanned aerial vehicles (UAVs), can play…

Drone Racing: The Emergence of a High-Speed Spectator Sport
Drone racing has emerged as an exciting and high-speed spectator sport that combines technology, skill, and adrenaline. It involves pilots maneuvering small, agile drones through obstacle-filled courses at high speeds, often with first-person view (FPV)…
Agricultural Drones: Transforming Farming Practices and Crop Management
Agricultural drones, also known as farm drones or agricultural UAVs, are unmanned aerial vehicles specifically designed for applications in agriculture. These drones are equipped with various sensors, cameras, and imaging technologies that enable farmers to…

Drone Delivery for Medical Emergencies: Improving Access to Critical Supplies
Drone delivery for medical emergencies has emerged as a promising solution to improve access to critical supplies in remote or hard-to-reach areas, as well as during urgent situations where timely delivery is crucial. Here are…

Drone-based Infrastructure Inspection: Enhancing Safety and Efficiency in Construction
Drone-based infrastructure inspection has become increasingly popular in the construction industry, offering numerous benefits in terms of safety, efficiency, and cost-effectiveness. Drones, also known as unmanned aerial vehicles (UAVs), provide a unique vantage point for…
Drone-based Environmental Monitoring: Tracking Climate Change and Wildlife Conservation
Drone-based environmental monitoring has emerged as a valuable tool for tracking climate change and supporting wildlife conservation efforts. Drones, also known as unmanned aerial vehicles (UAVs), offer unique advantages in terms of data collection, accessibility,…

Drone-based Inspection and Maintenance: Enhancing Safety and Efficiency in Infrastructure
Drone-based inspection and maintenance is a rapidly growing application of unmanned aerial vehicles (UAVs) that is revolutionizing the way infrastructure is monitored and maintained. Drones equipped with cameras, sensors, and imaging technology can provide detailed…

Drone Regulation and Airspace Management: Balancing Safety and Innovation
Drone regulation and airspace management play a crucial role in balancing safety and innovation in the use of unmanned aerial vehicles (UAVs). As drones become more prevalent in various industries and recreational use, it is…

Solar-powered Drones: Prolonging Flight Time and Expanding Applications
Solar-powered drones, also known as solar drones or solar-powered unmanned aerial vehicles (UAVs), are drones that utilize solar energy as their primary power source. These…

The Rise of Autonomous Drones: Advancements in AI and Robotics
The rise of autonomous drones represents a significant advancement in the fields of artificial intelligence (AI) and robotics. Autonomous drones, also known as unmanned aerial…
Delivery Drones: Transforming Logistics and Last-Mile Delivery
Delivery drones are unmanned aerial vehicles (UAVs) that can transport packages, food, and other goods to customers in a faster, more efficient way than traditional…

Counter-Drone Technology: Mitigating Security Risks and Protecting Against Unauthorized Drones
Counter-drone technology refers to the set of tools and measures designed to mitigate security risks and protect against unauthorized or malicious drones. As the popularity…

What are drone technology and types of drones thriving in today’s market?
The drone is becoming the hottest topic in the room and along with it is also tempting huge investments encouraging further advancements in drone technology. …

Future of drone technology in defense
Drones have got several names in the present technological era, such as a mini flying robot, unnamed aerial vehicles, mini pilotless aircraft, and more. Regardless…

Drone Swarms: Exploring the Potential of Collaborative Aerial Systems
Drone swarms refer to a group of drones that fly in coordinated patterns, similar to the behavior of a flock of birds or a school…

Industrial usage of drones
Drones were expensive enough to be accepted by any business for its development but were initially only accepted by the defense sector for remote surveillance.…

Drone-based 3D Mapping and Surveying: Revolutionizing Geospatial Data Collection
Drone-based 3D mapping and surveying refer to the use of unmanned aerial vehicles (UAVs), commonly known as drones, to collect and process geospatial data in…

Beyond Visual Line of Sight (BVLOS) Operations: Overcoming Regulatory and Technological Challenges
Beyond Visual Line of Sight (BVLOS) operations refer to the operation of unmanned aerial vehicles (UAVs) or drones beyond the direct sight of the operator.…

Challenges confronting enterprises in developing fully autonomous drone
Drone is undoubtedly a technology which is benefiting various business sectors with a number of aspects. But the acceptance of drone technology is not as…

Application of drone technology
Drone technology was one of the most expensive technologies inaccessible for most of the businesses. The advancement of technology has improved the development of drones…

Drone Integration with Internet of Things (IoT): Enabling Smart and Connected Environments
The integration of drones with the Internet of Things (IoT) is a powerful combination that enables the creation of smart and connected environments. By connecting…

Artificial Intelligence (AI) and Machine Learning in Cybersecurity: Strengthening Defense Against Advanced Threats
Artificial intelligence (AI) and machine learning have emerged as valuable tools in strengthening defense against advanced cybersecurity threats. Here's how AI and machine learning contribute to cybersecurity: Threat Detection and Prevention: AI algorithms can analyze large…

Data Privacy and Compliance: Navigating Regulations in an Evolving Landscape
Data privacy and compliance are critical considerations for organizations of all sizes and types. Here are some strategies that can be used to navigate data privacy regulations…

Cybersecurity Skills Gap: Meeting the Growing Demand for Cybersecurity Professionals
The cybersecurity skills gap is a growing concern, as the demand for cybersecurity professionals continues to outstrip supply. Here are some strategies that can be used to…

Mobile Device Security: Addressing Threats and Protecting Sensitive Data
Mobile device security is crucial in today's digital landscape, as smartphones and tablets store and access a wealth of sensitive information. To address threats and protect sensitive…

Cybersecurity Imperatives for Future CIOs: Protecting Data in the Age of Sophisticated Threats
As the digital landscape evolves, cybersecurity has become a critical concern for organizations of all sizes. Future Chief Information Officers (CIOs) need to prioritize cybersecurity and implement…

The Human Element of Cybersecurity: Understanding and Mitigating Insider Threats
The human element of cybersecurity is critical to understand and mitigate insider threats. Insider threats refer to security risks posed by individuals within an organization who have…

The Impact of 5G: How CIOs Can Prepare Their Organizations for the Next Generation of Connectivity
The advent of 5G technology brings significant opportunities and challenges for organizations. As CIOs prepare their organizations for the next generation of connectivity, here are some key…

Cybersecurity in the Era of 5G: Addressing Security Challenges in the Next Generation of Connectivity
The advent of 5G, the fifth generation of cellular mobile communications, promises faster data transmission speeds, lower latency, and greater connectivity than previous generations of wireless networks.…
Supply Chain Security: Safeguarding the Digital Supply Chain from Cyber Attacks
Safeguarding the digital supply chain from cyber attacks is crucial to ensure the integrity, confidentiality, and availability of products, services, and data. Here are some key steps…

Multi-Factor Authentication: Strengthening Access Controls and Authentication Mechanisms
Multi-factor authentication (MFA) is a security mechanism that requires users to provide multiple forms of identification to access a system, application, or service. This approach helps to…

Cyber Threat Hunting: Proactive Approaches to Identifying and Responding to Cyber Threats
Cyber threat hunting is a proactive approach to identifying and responding to cyber threats. Rather than waiting for a security breach to occur, threat hunting involves actively…

Securing Artificial Intelligence (AI) Systems: Mitigating Risks and Ensuring Trustworthiness
Securing artificial intelligence (AI) systems is crucial to mitigate risks and ensure the trustworthiness of AI applications. Here are key considerations for enhancing the security of AI…

Securing the Remote Workforce: Challenges and Solutions in a Distributed Work Environment
Securing the remote workforce in a distributed work environment presents unique challenges due to the increased reliance on remote technologies and potential vulnerabilities. Here are…

Cybersecurity in Critical Infrastructure: Protecting Essential Services and Systems
Cybersecurity in critical infrastructure is essential to protect essential services and systems that are vital to the functioning of society. Here are some strategies and…

Cloud Security: Emerging Trends and Best Practices for Protecting Data in the Cloud
Cloud security is a critical aspect of modern cybersecurity, as more organizations are migrating their data and applications to the cloud. Here are some emerging…

Threat Intelligence and Information Sharing: Collaborative Approaches to Cyber Defense
Threat intelligence and information sharing play vital roles in collaborative approaches to cyber defense. By sharing information about cybersecurity threats, attacks, and vulnerabilities, organizations can…

Ransomware Defense: Strategies and Technologies for Detecting, Preventing, and Recovering
Ransomware is a growing threat to organizations and individuals alike. Here are some strategies and technologies that can be used to detect, prevent, and recover…

New-Gen Cybersecurity Ensured
GLAZA: Digitalizing automotive sector Denis Kulikov is a leader with experience in Project Management – Computer vision, software development and applied Artificial Intelligence (AI). He…

Biometrics and Identity Authentication: Advancements in Secure Access Control
Biometrics and identity authentication are advancing rapidly, and these technologies are increasingly being used for secure access control. Here are some of the advancements in…

Internet of Things (IoT) Security: Securing Connected Devices and Networks
Securing the Internet of Things (IoT) is crucial as the number of connected devices continues to grow rapidly. IoT security focuses on protecting connected devices,…
Blockchain and Cybersecurity: Enhancing Trust and Integrity in Digital Transactions
Blockchain technology has the potential to enhance trust and integrity in digital transactions, as it provides a secure, transparent, and immutable ledger of transactions. Here…

Reduce data security risks with Cyber security
Have you ever felt afraid of whether your confidential data will be damaged? If the answer is yes, you are really afraid of cyber-attacks and…

The Perfect Mediator for Secured Data Sharing
The Perfect Mediator for Secured Data Sharing With data flood on the rise, the need to securely access/share data has become a major challenge like…

Data-centric Security at its Best
Data-centric Security at its Best “It will add mindfulness to the way employees perform their jobs with a security first mentality,” says Brian Arellanes, Founder…

Artificial Intelligence (AI) and Machine Learning in Cybersecurity: Strengthening Defense Against Advanced Threats
Artificial intelligence (AI) and machine learning have emerged as valuable tools in strengthening defense against advanced cybersecurity threats. Here's how AI and machine learning contribute…

IoT in Healthcare: Enhancing Patient Monitoring and Remote Care
IoT (Internet of Things) is playing a significant role in transforming the healthcare industry by enabling enhanced patient monitoring and remote care. The integration of…

IoT and Predictive Maintenance: Reducing Downtime and Increasing Efficiency
The integration of IoT (Internet of Things) and predictive maintenance techniques has revolutionized the way industries manage and maintain their equipment. Predictive maintenance leverages IoT devices and data analytics to…

Privacy and Ethical Considerations in IoT: Balancing Innovation and Data Protection
As the Internet of Things (IoT) continues to expand and connect more devices and systems, it raises important privacy and ethical considerations that must be carefully addressed to strike a…

The Future of IoT: Interoperability, Standards and Scalability Challenges
While the Internet of Things (IoT) holds immense potential for transforming industries and our daily lives, there are several challenges that need to be addressed for its future success. Interoperability,…

IoT in Retail: Personalizing Customer Experiences and Supply Chain Optimization
IoT (Internet of Things) technology is reshaping the retail industry by enabling personalized customer experiences and optimizing supply chain operations. By connecting physical objects and devices to the internet, IoT…

Blockchain and IoT: Enhancing Security and Trust in Connected Devices
The combination of blockchain technology and IoT (Internet of Things) has the potential to enhance security, privacy, and trust in connected devices and networks. Blockchain, a decentralized and tamper-resistant digital…

IoT and Wearable Technology: The Future of Personal Health Monitoring
The combination of IoT (Internet of Things) and wearable technology is driving the future of personal health monitoring, empowering individuals to track and manage their health in real time. Wearable…
IoT and Transportation: Advancements in Connected Vehicles and Smart Logistics
The integration of IoT (Internet of Things) technology in transportation is revolutionizing the way vehicles operate and logistics are managed. Connected vehicles and smart logistics solutions powered by IoT offer…

IoT Data Analytics: Extracting Actionable Insights from Massive Data Streams
IoT (Internet of Things) data analytics is a process of extracting valuable insights and actionable information from the massive streams of data generated by IoT devices and systems. With billions…
IoT and Environmental Monitoring: Tracking and Mitigating Climate Change Impacts
The combination of IoT (Internet of Things) and environmental monitoring has become a powerful tool in tracking and mitigating the impacts of climate change. IoT devices, such as sensors and…

Embracing IoT: CIOs’ Guide to Harnessing the Power of the Internet of Things
The Internet of Things (IoT) presents tremendous opportunities for organizations to enhance operational efficiency, improve decision-making, and drive innovation. As CIOs navigate the adoption of IoT, here is a guide…

Telit Introduces OneEdge and Shortens Path to IoT Monetization
Telit Introduces OneEdge and Shortens Path to IoT Monetization Telit OneEdge is a next generation software suite for…

IoT in Agriculture: Improving Crop Yield and Farming Practices
IoT (Internet of Things) technology is playing a significant role in revolutionizing agriculture and improving crop yield and…

Smart Cities: Harnessing IoT for Sustainable Urban Development
Smart cities are urban environments that leverage the Internet of Things (IoT) and other technologies to enhance the…

IoT: Giving a new dimension to the world of internet
There are billions of devices round the world with a huge amount of data stored and transferred using…

IoT and Energy Management: Optimizing Resource Efficiency and Sustainability
IoT (Internet of Things) technology is playing a significant role in energy management by optimizing resource efficiency and…

5G and IoT: Enabling the Next Generation of Connected Devices and Applications
5G and the Internet of Things (IoT) are two technologies that complement each other and are driving the…

Amazing developments in the sector of IoT
We are living in a world where every single thing, every single person is dependent on technology and…

IoT Security: Addressing the Growing Concerns of Device Vulnerabilities
IoT security is a critical aspect of the growing IoT landscape as it addresses the concerns of device…

Digital Twins: Creating Virtual Models for IoT-enabled Predictive Maintenance
Digital twins refer to virtual replicas or models of physical objects, processes, or systems. In the context of…
Edge Computing in IoT: Transforming Data Processing and Real-Time Analytics
Edge computing in the context of the Internet of Things (IoT) refers to the decentralized processing and analysis…

IoT in Healthcare: Enhancing Patient Monitoring and Remote Care
IoT (Internet of Things) is playing a significant role in transforming the healthcare industry by enabling enhanced patient…

Industrial IoT (IIoT): Revolutionizing Manufacturing and Supply Chain Management
Industrial Internet of Things (IIoT) refers to the application of IoT technologies and solutions in industrial settings, such…

IoT and Smart Homes: Creating Intelligent and Connected Living Spaces
IoT (Internet of Things) technology is transforming traditional homes into smart homes by creating intelligent and connected living…


Talent Acquisition and Skills Gap: Building a Skilled Marketing Technology Team
Building a skilled marketing technology team requires a thoughtful approach to talent acquisition and addressing skills gaps. Here are strategies to build a skilled marketing…

Technology Adoption and Change Management: Overcoming Resistance and Driving Organizational Alignment
Technology adoption and change management are critical for driving successful implementation of marketing technology and ensuring organizational alignment. However, resistance to change is a common challenge that can hinder progress.…

Managing Customer Data: Ensuring Compliance and Ethical Use in Marketing Technology
Managing customer data and ensuring compliance and ethical use in marketing technology is of utmost importance to maintain customer trust and comply with legal and ethical standards. Here are some…

Integration and Interoperability Challenges: Bridging Gaps between Marketing Technology Systems
Integration and interoperability challenges are common when it comes to bridging gaps between marketing technology systems. Here are some strategies to overcome these challenges and achieve seamless integration: Define Integration…

The Human Factor: Balancing Automation and Personalization in Marketing Technology
Balancing automation and personalization in marketing technology is crucial to deliver effective and personalized customer experiences while maintaining efficiency and scalability. Here are some considerations to manage the human factor…

Multichannel Attribution Challenges: Understanding the Customer Journey in a Fragmented Marketing Landscape
Understanding the customer journey and accurately attributing conversions across multiple channels can be challenging in a fragmented marketing landscape. Here are strategies to address multichannel attribution challenges and gain insights…

The Role of AI Bias in Marketing Technology: Mitigating Unintended Consequences
The role of AI bias in marketing technology is a critical consideration when leveraging artificial intelligence and machine learning algorithms. AI bias refers to the unintended favoritism or discrimination that…

Scaling Personalization: Overcoming the Challenges of Delivering Customized Experiences at Scale
Scaling personalization and delivering customized experiences at scale can be challenging, but it is essential to meet customer expectations and drive marketing success. Here are some strategies to overcome the…

User Experience Challenges in Marketing Technology: Designing Seamless and Intuitive Customer Journeys
Designing seamless and intuitive customer journeys is essential in marketing technology to enhance user experience…

Cybersecurity in Marketing Technology: Protecting Customer Data and Preventing Data Breaches
Cybersecurity is a critical aspect of marketing technology to protect customer data and prevent data…

Talent Acquisition and Skills Gap: Building a Skilled Marketing Technology Team
Building a skilled marketing technology team requires a thoughtful approach to talent acquisition and addressing…
Measuring Marketing Technology Success: Metrics and KPIs for Effective Performance Evaluation
Measuring the success of marketing technology initiatives requires defining appropriate metrics and Key Performance Indicators…

Marketing Technology Governance: Establishing Policies and Processes for Effective Management
Marketing technology governance is crucial for effective management and utilization of marketing technology within an…

Managing Complexity: Addressing the Challenges of Marketing Technology Stack Integration
Integrating a marketing technology stack can be complex due to the diverse range of tools,…

Adapting to Changing Consumer Privacy Regulations: Navigating the Challenges in Marketing Technology
Consumer privacy regulations, such as the General Data Protection Regulation (GDPR) and the California Consumer…

Real-Time Marketing Challenges: Staying Agile in an Ever-Changing Digital Landscape
Staying agile in an ever-changing digital landscape is crucial for real-time marketing success. Here are…

Balancing Automation and Creativity: Fostering Human-Centric Marketing in Technology-Driven Environments
Balancing automation and creativity is crucial for fostering human-centric marketing in technology-driven environments. While automation…
Cloud Robotics: Transforming Robotics with Cloud Connectivity and Data Processing
Cloud robotics is a field that combines robotics with cloud computing technologies, enabling robots to leverage the power of cloud connectivity and data processing. It…

Cloud Security: Innovations and Best Practices for Protecting Data in the Cloud
Cloud security is a critical concern for organizations that rely on cloud computing to store, process, and transmit sensitive data. While cloud computing offers many benefits,…

Serverless AI: The Intersection of Serverless Computing and Artificial Intelligence
Serverless AI is the convergence of serverless computing and artificial intelligence (AI) technologies. Serverless computing, also known as Function as a Service (FaaS), is an execution…
Cloud Computing and Internet of Things (IoT): Transforming Industries and Smart Solutions
Cloud computing and Internet of Things (IoT) are two transformative technologies that have the potential to significantly impact industries and enable new smart solutions. The combination…

Cloud-native Database Systems: Harnessing the Power of Distributed Databases
Cloud-native database systems refer to databases that are specifically designed to operate in cloud environments and leverage the benefits of cloud computing. These systems are built…

Cloud Data Analytics: Leveraging Cloud Computing for Advanced Data Insights
Cloud data analytics is the practice of leveraging cloud computing resources to perform advanced data analytics and gain insights from large datasets. The cloud offers numerous…

Cloud Automation and Orchestration: Streamlining Operations and Management
Cloud automation and orchestration refer to the use of tools, processes, and frameworks to automate and streamline the deployment, management, and operation of cloud-based resources and…

Cloud Quantum Computing: Exploring the Potential for Quantum Computing in the Cloud
Cloud quantum computing refers to the use of quantum computing resources in the cloud. This technology has the potential to revolutionize computing, as quantum computers are…

Cloud-Native Networking: Advancements in Cloud Networking Technologies
Cloud-native networking refers to the use of networking technologies and architectures that are specifically designed for cloud environments. It focuses on providing scalable, flexible, and resilient…

The Rise of Cloud Computing: Challenges and Opportunities for CIOs
The rise of cloud computing has brought about significant challenges and opportunities for Chief Information Officers (CIOs). Cloud computing offers numerous benefits, such as scalability, flexibility,…

Cloud-Native Storage: Optimizing Data Storage and Retrieval in the Cloud
Cloud-native storage is an approach to data storage that is designed specifically for the cloud computing environment. Unlike traditional storage systems that were designed for on-premise…

Edge-to-Cloud Data Processing: Balancing Processing Power between Edge Devices and Cloud
Edge-to-Cloud data processing refers to the approach of analyzing and processing data at the edge of the network (close to where the data is generated) and…

Empower your business with the next level of Cloud Computing
From Applications to storage and processing power, under the umbrella of cloud computing, it includes the process of delivery of…

Hybrid Cloud and On-Premises Integration: Creating a Seamless Hybrid IT Environment
Hybrid cloud and on-premises integration refers to the practice of seamlessly integrating resources and workloads across both public or private…

Cloud technology: The new face of today’s start-up
Startups are growing at the fastest pace bringing astonishing and creative ideas into vitality using the latest technologies. The inception…

Artificial Intelligence and Machine Learning in Cloud Computing: Advancements and Opportunities
Artificial Intelligence (AI) and Machine Learning (ML) have had a significant impact on cloud computing, enabling advancements and creating new…

Advantages of Cloud Computing for business development
Traditional business strategies were much bonded within papers and offered limited access. With the emergence of cloud computing most of…

Multi-Cloud Strategies: Harnessing the Power of Multiple Cloud Providers
Multi-cloud strategy involves the use of two or more cloud computing services, often from different providers, to meet an organization's…
Blockchain and Cloud Computing Integration: Exploring the Potential for Trust and Transparency
The integration of blockchain and cloud computing can offer significant potential for enhancing trust and transparency in various industries. Blockchain…

Upscale your business with Cloud Computing
Cloud Computing is a broad term that refers to a collection of services that offer businesses a cost-effective solution to…

The Rise of Edge Computing: How Cloud Computing is Evolving to the Edge
Edge computing is a new paradigm in computing that has emerged in response to the growth of the Internet of…

Quantum Computing and Cloud: The Convergence of Two Disruptive Technologies
Quantum computing and cloud computing are two rapidly evolving and disruptive technologies that are transforming the landscape of computing. Quantum…

Serverless Computing: The Future of Cloud Infrastructure
Serverless computing, also known as Function-as-a-Service (FaaS), is an emerging paradigm in cloud computing that is rapidly gaining popularity. It…

Accelerate Business growth with Cloud Computing
Cloud Computing is the process of outsourcing of software, data storage, and processing. With the help of an internet connection,…

Cloud-Native Architecture: Enabling Scalability and Agility in the Cloud
Cloud-native architecture refers to a design approach that takes full advantage of cloud computing principles and services to build and…

The Impact of 5G on AR/VR: Enabling Low Latency and High-Quality Experiences
The advent of 5G technology has significant implications for the advancement and widespread adoption of AR (Augmented Reality) and VR (Virtual Reality). With its high-speed,…

AR/VR in Sports: Enhancing Fan Engagement and Athlete Training
AR (Augmented Reality) and VR (Virtual Reality) technologies have made a significant impact on the world of sports, enhancing fan engagement and revolutionizing athlete training.…

Social Virtual Reality: Connecting People in Virtual Worlds and Shared Experiences
Social Virtual Reality (VR) is a dynamic and immersive technology that enables people to connect and interact with each other in virtual worlds, fostering shared…

How CIOs Can Foster a Culture of Continuous Technological Advancement
To foster a culture of continuous technological advancement and drive digital disruption and innovation within an organization, CIOs can take several key steps: Establish a…

The Future of AR Glasses and VR Headsets: Advancements in Hardware and Design
The future of AR glasses and VR headsets is poised for significant advancements in hardware and design, offering more immersive, comfortable, and versatile experiences. Here…

AR/VR for Mental Health: Therapeutic Applications and Stress Reduction
AR (Augmented Reality) and VR (Virtual Reality) technologies are increasingly being utilized for therapeutic applications and stress reduction in the field of mental health. These…

Immersive Advertising: Engaging Consumers through AR/VR Experiences
Immersive advertising through Augmented Reality (AR) and Virtual Reality (VR) experiences is revolutionizing the way brands engage with consumers. By leveraging the power of AR/VR…

The Role of Haptics in AR/VR: Adding a Sense of Touch to Virtual Experiences
Haptics, the science of touch, plays a vital role in augmenting virtual experiences in Augmented Reality (AR) and Virtual Reality (VR). By incorporating haptic feedback,…

Augmented Reality in Manufacturing and Industrial Processes: Improving Efficiency and Safety
Augmented Reality (AR) is transforming manufacturing and industrial processes by improving efficiency, safety, and productivity. By overlaying digital information onto the physical world, AR enhances…

Immersive Storytelling: Redefining Narrative Experiences through AR/VR
Immersive storytelling in AR (Augmented Reality) and VR (Virtual Reality) is revolutionizing the way narratives are created and experienced. By leveraging the power of these…

AR/VR for Training and Simulation: Improving Skills Development and Performance
Augmented Reality (AR) and Virtual Reality (VR) technologies are revolutionizing training and simulation across various industries. By creating immersive and interactive experiences, AR/VR enables realistic…

AR/VR in Architecture and Design: Visualizing Spaces and Enhancing Creativity
AR (Augmented Reality) and VR (Virtual Reality) technologies have revolutionized the field of architecture and design by providing powerful tools for visualizing spaces and enhancing…

AR/VR and Cultural Heritage: Preserving and Reviving Historical Sites and Artifacts
AR/VR technologies are playing a significant role in preserving and reviving cultural heritage by offering immersive and interactive experiences that bring historical sites and artifacts…

Virtual Reality Gaming: The Evolution of Immersive Entertainment
Virtual Reality (VR) gaming has emerged as a transformative technology in the entertainment industry, offering players an unprecedented level of immersion and interactivity. Over the…
The Future of AR/VR: Transforming the Way We See and Interact with the World
The future of Augmented Reality (AR) and Virtual Reality (VR) holds tremendous potential to revolutionize the way we perceive and interact with the world around…

Human Sensory Possibility of Virtual Reality
When we talk about perception, we include a number of senses in it, namely vision, physical touch, auditory, gustatory, and nociceptive senses and more. Even…

AR/VR in Education: Enhancing Learning Experiences and Immersive Education
AR (Augmented Reality) and VR (Virtual Reality) technologies have tremendous potential to enhance learning experiences and provide immersive education in various fields. By blending the…

What is virtual reality and how it is affecting the real world?
A moving clip displayed on a screen was a miracle in olden days and even if you turn back to the past decade then also…

AR/VR in Healthcare: Advancements in Medical Training and Patient Care
Augmented Reality (AR) and Virtual Reality (VR) technologies have significant applications in the healthcare industry, revolutionizing medical training and patient care. These immersive technologies offer…

Miracles of virtual reality in physical therapy
Every year, there are more than a billion people struggle from strokes and traumatic brain injuries. These injuries are curable and require physical therapies to…

AR in Retail: Revolutionizing the Shopping Experience and Personalized Marketing
Augmented reality (AR) is revolutionizing the retail industry by transforming the shopping experience and enabling personalized marketing strategies. AR technology overlays digital content onto the…

What are the advanced applications of virtual reality?
Virtual reality is gaining a rapid popularity among folks due to its amazing features that let you penetrate into a virtual world and experience it…
Virtual Collaboration: Transforming Remote Work and Team Communication
Virtual collaboration is transforming the way people work and communicate in remote settings. With the advancements in technology and the rise of remote work, virtual…

Mixed Reality: Bridging the Gap between the Real and Virtual Worlds
Mixed Reality (MR) is a technology that blends elements of both virtual reality (VR) and augmented reality (AR) to create a seamless and interactive experience,…

Immersive Virtual Travel: Exploring Destinations from the Comfort of Your Home
Immersive virtual travel is a fascinating application of technology that allows individuals to explore destinations and experience different cultures from the comfort of their homes.…

Challenges faced by Virtual reality to become reality
Virtual reality is undoubtedly a great innovation having the potential to change several industries. Every excellent innovation has some loopholes that makes the technology incomplete…

Space Exploration and Colonization: Future Missions and Habitation
Space exploration and colonization have been subjects of interest and research for several decades. While significant progress has been made, there is still much to learn and achieve in these areas. Here are some aspects related to future missions and…

The Role of Artificial Intelligence (AI) in Defense Systems and Decision-Making
Artificial Intelligence (AI) plays a significant role in defense systems and decision-making processes, offering numerous benefits and capabilities. Here are some key aspects of AI's role in…

Strategic Missile Defense Systems: Detecting and Intercepting Threats
Strategic missile defense systems are designed to detect and intercept incoming ballistic missiles, providing protection against potential missile threats. These systems employ a combination of technologies and…

Augmented Reality in Aviation: Enhancing Pilot Training and Maintenance Operations
Augmented Reality (AR) technology is making significant strides in the aviation industry, particularly in the areas of pilot training and maintenance operations. By overlaying digital information onto…

Advanced Materials in Aerospace: Lighter, Stronger, and More Efficient Structures
Advanced materials play a crucial role in aerospace engineering, enabling the development of lighter, stronger, and more efficient structures for aircraft and spacecraft. These materials offer numerous…

Quantum Computing and Aerospace: Revolutionizing Data Processing and Analysis
Quantum computing has the potential to revolutionize data processing and analysis in the aerospace industry. Traditional computers, based on classical computing principles, have limitations in solving complex…

Cybersecurity in Aerospace and Defense: Protecting Critical Infrastructure
Cybersecurity plays a crucial role in the aerospace and defense industry, especially when it comes to protecting critical infrastructure. Aerospace and defense organizations handle sensitive data and…
The Evolving Role of CIOs: Navigating Digital Transformation in a Rapidly Changing Landscape
The role of Chief Information Officers (CIOs) has been undergoing significant changes in recent years, primarily due to the rapid pace of digital transformation. As organizations embrace…

Advanced Robotics and Automation in Aerospace Manufacturing
Advanced robotics and automation play a crucial role in aerospace manufacturing, enabling increased productivity, precision, and efficiency in various processes. Here are some key areas where advanced…

Hypersonic Flight: Pushing the Boundaries of Speed and Efficiency
Hypersonic flight refers to the ability to travel at speeds exceeding Mach 5 (approximately 6,174 kilometers per hour or 3,836 miles per hour), which is…

Drone technology: A new face of aerospace and defense industry
Drones, also known as unnamed aerial vehicles (UAVs) are an amazing innovation which can be considered as a miniature pilotless aircrafts in the air preprogrammed…

How cyber security plays a crucial role in defense industry?
In defense sector every minute is important, a delay of single minute can create big loses. Defense requires a technology which is efficient, prompt, and…

Aerospace and Defense Industry Outlook in 2020
The year 2020 has come up with several challenges for everyone. None of the business industries are untouched from its impact and so the aerospace…

The Future of Aerospace and Defense Technology: Innovations Shaping the Industry
The aerospace and defense industry is constantly evolving, driven by technological advancements and the need for innovative solutions. Here are some key innovations that are…

Electric Propulsion in Aviation: Advancements in Sustainable Aircraft Design
Electric propulsion in aviation is a rapidly developing area that aims to revolutionize aircraft design and make aviation more sustainable. Traditional aircraft propulsion systems rely…

Next-Generation Fighter Jets: Stealth Technology and Advanced Avionics
Next-generation fighter jets are being developed with cutting-edge technologies to ensure superior capabilities on the modern battlefield. Two key areas of focus are stealth technology…

Space Tourism: Opening the Doors to Commercial Space Travel
Space tourism is an emerging industry that aims to make space travel accessible to private individuals who are not professional astronauts. It holds the promise…

What’s on the horizon of aerospace and defence industry in upcoming years?
Technological advancement is acting like the DNA for various business sectors. There are several non-technical industries too that are incorporating latest technologies and giving a…

Space Exploration and Colonization: Future Missions and Habitation
Space exploration and colonization have been subjects of interest and research for several decades. While significant progress has been made, there is still much to…

Biomanufacturing: Scaling Up Production of Biopharmaceuticals and Biochemicals
Biomanufacturing, also known as bio-based manufacturing or bio-production, involves the use of living organisms, such as bacteria, yeast, or mammalian cells, to produce a wide…

Bio-inspired Design: Taking Cues from Nature for Engineering Solutions
Bio-inspired design, also known as biomimicry or biologically inspired engineering, involves drawing inspiration from nature's principles, structures, and processes to develop innovative solutions for various…

Precision Agriculture: Enhancing Crop Yield and Sustainability
Precision agriculture, also known as precision farming or smart farming, is an approach that utilizes advanced technologies and data analytics to optimize agricultural practices. It…

Nanotechnology in Biomedicine: Targeted Drug Delivery and Diagnostics
Nanotechnology, the manipulation of matter on a nanoscale level, has made significant advancements in the field of biomedicine. It offers unique capabilities for targeted drug…

Synthetic Biology: Engineering Life for Industrial and Medical Applications
Synthetic biology is an interdisciplinary field that combines biology, engineering, and computer science to design and construct new biological parts, devices, and systems, or to…

Biofuels and Sustainable Energy: Biomass Conversion and Alternative Fuel Sources
Biofuels play a significant role in the pursuit of sustainable energy sources and reducing greenhouse gas emissions. They are derived from renewable biomass, such as…

Bioinformatics and Data Analytics: Unleashing the Power of Biological Big Data
Bioinformatics and data analytics play a crucial role in harnessing the potential of biological big data. With the advancement of high-throughput technologies, the volume and…
Microbiome Research: Understanding the Role of Gut Microbes in Health and Disease
Microbiome research focuses on understanding the role of the vast community of microorganisms that inhabit the human body, particularly the gut microbiome, in health and…

Stem Cell Research: Harnessing the Power of Cellular Regeneration
Stem cell research harnesses the power of cellular regeneration and has the potential to revolutionize medicine and our understanding of human biology. Stem cells are…

Environmental Biotechnology: Addressing Pollution and Waste Management
Environmental biotechnology is a field that utilizes biological processes and organisms to address environmental challenges, particularly in pollution control and waste management. It harnesses the…

Antibiotics & Vaccines: A gift of Biotechnology
The world has gone digitized, super swift, high tech, and a lot more advancement have been witnessed by the folks…

The Future of Biotechnology: Innovations Driving Medical Breakthroughs
The future of biotechnology holds great promise in driving medical breakthroughs and transforming healthcare. Here are some innovations that are…
Gene Editing and CRISPR Technology: Transforming Genetic Therapies
Gene editing and CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats) technology have indeed transformed the field of genetic therapies and…

Biotechnology promoting green energy
In the hustle and bustle of life, almost 95% folks use vehicles to match the speed of this running world.…

Applications of environmental biotechnology
Technological growth has given a new world to live and every single folk is enjoying the rapid advancements and its…
Biotechnology endorsing health solutions
As a wise man said “Health is wealth”, but in today’s hustling and bustling life health is not kept as…

Recombination of DNA: A drift of transformation in medical sector
Technology of recombining DNA was discovered years ago and now it is gaining higher values in the medical sector. With…

Importance of Cell biology
Falling ill in our day to day life is a commonly seen scenario. In a day approx. 30% of folks…

BioTech In The Sector Of Disease Diagnosis & Its Treatment
Using a living organism for the improvement or reconstruction of a product is termed as biotechnology. Creation of any animal,…

Medical Implants and Bioelectronics: Merging Technology with Biology
Medical implants and bioelectronics represent the integration of technology with biology to develop advanced devices that interface with the human…

Exciting Development In The Sector Of Biotechnology
Evolution of technological growth is at its peak and every day is coming you with new and more effective approach…
Bioprinting A Transformation In The Sector Of Medical Science
Medical is one of the most important sectors not only in terms of technological growth but as a life savior.…